Arbeiten mit großen CSV-Dateien in Python
Daten spielen eine Schlüsselrolle beim Aufbau des maschinellen Lernens und des KI-Modells. In der heutigen Welt, in der Daten mit astronomischer Geschwindigkeit von jedem Computergerät und Sensor generiert werden, ist es wichtig, riesige Datenmengen korrekt zu handhaben. Eine der gebräuchlichsten Möglichkeiten zum Speichern von Daten ist die Form von kommagetrennten Werten (CSV) . Das direkte Importieren einer großen Datenmenge führt zu Speichermangelfehlern und das Lesen der gesamten Datei auf einmal führt zu Systemabstürzen aufgrund von unzureichendem RAM.
Im Folgenden finden Sie einige Möglichkeiten zum effektiven Umgang mit großen Datendateien im CSV-Format. Der Datensatz, den wir verwenden werden, ist gender_voice_dataset .
pandas.read_csv(chunksize) verwenden
Eine Möglichkeit, große Dateien zu verarbeiten, besteht darin, die Einträge in Blöcken angemessener Größe zu lesen, die in den Speicher eingelesen und verarbeitet werden, bevor der nächste Block gelesen wird. Wir können den Chunk-Size-Parameter verwenden, um die Größe des Chunks anzugeben, also die Anzahl der Zeilen. Diese Funktion gibt einen Iterator zurück, der zum Durchlaufen dieser Chunks verwendet wird, und verarbeitet sie dann. Da immer nur ein Teil der Datei gelesen wird, reicht wenig Arbeitsspeicher für die Verarbeitung aus.
Das Folgende ist der Code zum Lesen von Einträgen in Blöcken.
chunk = pandas.read_csv(filename,chunksize=...)
Der folgende Code zeigt die Zeit, die zum Lesen eines Datensatzes ohne Verwendung von Chunks benötigt wird:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time = time.time()
df = pd.read_csv("gender_voice_dataset.csv")
e_time = time.time()
print("Read without chunks: ", (e_time-s_time), "seconds")
# data
df.sample(10)
Ausgabe:
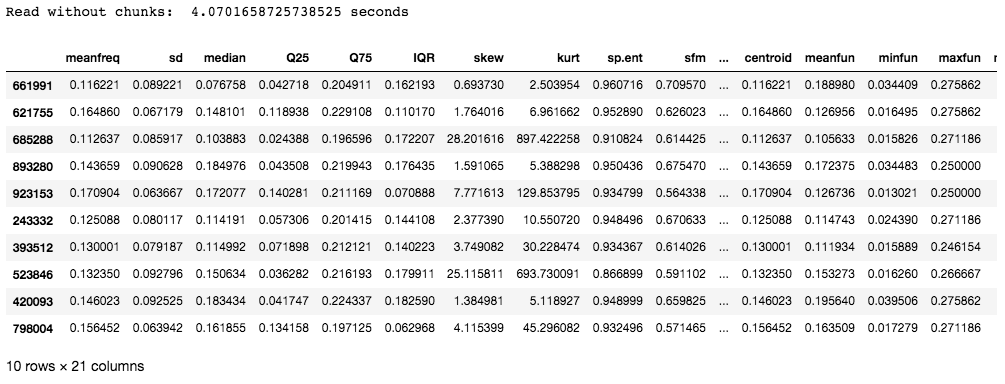
Der in diesem Beispiel verwendete Datensatz enthält 986894 Zeilen mit 21 Spalten. Die benötigte Zeit beträgt etwa 4 Sekunden, was vielleicht nicht so lang ist, aber bei Einträgen mit Millionen von Zeilen wirkt sich die zum Lesen der Einträge benötigte Zeit direkt auf die Effizienz des Modells aus.
Lassen Sie uns nun Chunks verwenden, um die CSV-Datei zu lesen:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time_chunk = time.time()
chunk = pd.read_csv('gender_voice_dataset.csv', chunksize=1000)
e_time_chunk = time.time()
print("With chunks: ", (e_time_chunk-s_time_chunk), "sec")
df = pd.concat(chunk)
# data
df.sample(10)
Ausgabe:
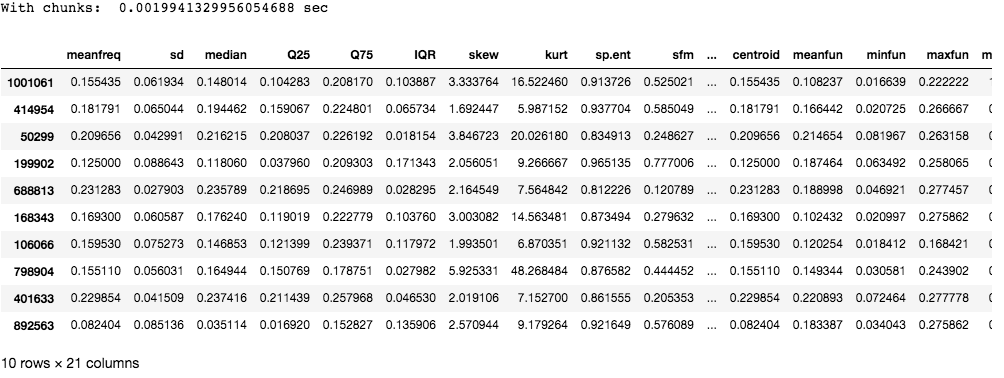
Wie Sie sehen können, dauert das Chunking viel weniger Zeit als das Lesen der gesamten Datei auf einmal.
Verwenden von Dask
Dask ist eine Open-Source-Python-Bibliothek, die Funktionen für Parallelität und Skalierbarkeit in Python enthält, indem vorhandene Bibliotheken wie Pandas, NumPy oder Sklearn verwendet werden.
Installieren:
pip install dask
Das Folgende ist der Code zum Lesen von Dateien mit dask:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
from dask import dataframe as df1
# time taken to read data
s_time_dask = time.time()
dask_df = df1.read_csv('gender_voice_dataset.csv')
e_time_dask = time.time()
print("Read with dask: ", (e_time_dask-s_time_dask), "seconds")
# data
dask_df.head(10)
Ausgabe:
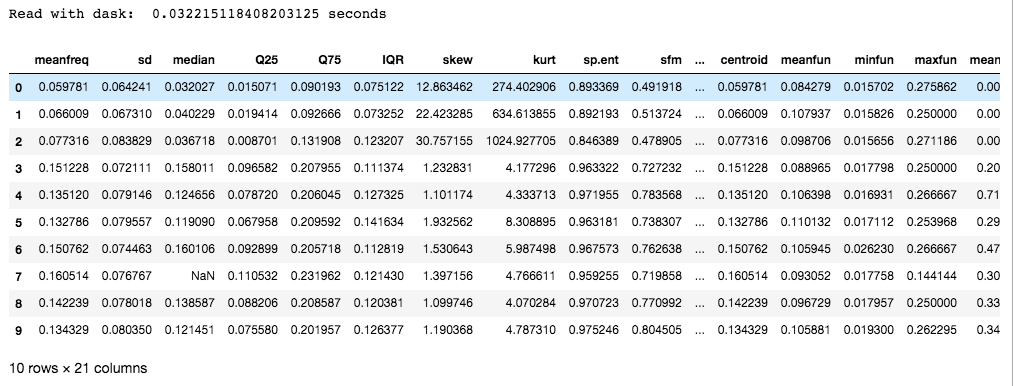
Dask wird dem Chunking vorgezogen, da es mehrere CPU-Kerne oder Computer-Cluster verwendet (bekannt als verteiltes Computing). Darüber hinaus bietet es auch skalierte NumPy-, Pandas- und Sci-Kit-Bibliotheken, um Parallelität auszunutzen.
Hinweis: Der Datensatz im Link hat etwa 3000 Zeilen. Zusätzliche Daten wurden für diesen Artikel separat hinzugefügt, um die Dateigröße zu erhöhen. Es existiert nicht im ursprünglichen Datensatz.