Bild GPT
Image GPT wurde von Forschern von OpenAI im Jahr 2019 vorgeschlagen. In diesem Artikel wird mit der Anwendung von GPT-ähnlichen Transformationen bei Objekterkennungs- / Objekterkennungsaufgaben experimentiert. Es gibt jedoch einige Herausforderungen für Autoren wie die Verarbeitung großer Bildgrößen usw.
Die Architektur:
Die Architektur von Image GPT (iGPT) ähnelt GPT-2, dh sie besteht aus einem Transformator-Decoderblock. Der Transformatordecoder verwendet eine Eingabesequenz x 1 ,…, x n diskreter Token und gibt für jede Position eine d-dimensionale Einbettung aus. Der Transformator kann als Stapel von Decodern der Größe L betrachtet werden , von denen der l-te eine Einbettung von h 1 l … .h n l erzeugt . Danach wird der Eingangstensor wie folgt an verschiedene Schichten übergeben:
- n l = Schichtnorm ( h l )
- a l = h l + Mehrkopfaufmerksamkeit ( n l )
- h l + 1 = a l + mlp (Schichtnorm (a l ))
Wobei Layer_Norm die Schichtnormalisierung ist und die MLP-Schicht ein mehrschichtiges Perzeptronmodell (künstliches neuronales Netzwerk) ist. Unten finden Sie eine Liste der verschiedenen Versionen
| Modellname / Variante | Eingangsauflösung | Parameter (M) | Eigenschaften |
|---|---|---|---|
| iGPT-Large (L) | 32 * 32 * 3 | 1362 | 1536 |
| 48 * 48 * 3 | |||
| iGPT-XL | 64 * 64 * 3 | 6801 | 3072 |
| 15360 |
Kontextreduktion:
Weil die Speicheranforderungen des Transformatordecoders bei Verwendung dichter Aufmerksamkeit quadratisch mit der Kontextlänge skalieren. Dies bedeutet, dass viel Rechenaufwand erforderlich ist, um auch nur einen einschichtigen Transformator zu trainieren. Um dies zu bewältigen, ändern die Autoren die Größe des Bildes auf niedrigere Auflösungen, die als Eingabeauflösungen (Input Resolutions, IRs) bezeichnet werden. Das iGPT-Modell verwendet IRs von 32 * 32 * 3 , 48 * 48 * 3 und 64 * 64 * 3 .
Trainingsmethode:
Das Modelltraining von Image GPT besteht aus zwei Schritten:
Vortraining
- Bei einem unbeschrifteten Datensatz X, der aus hochdimensionalen Daten x = (x 1 ,…, x n ) besteht, können wir eine Permutation π der Menge [1, n] auswählen und die Dichte p (x) automatisch regressiv wie folgt modellieren:
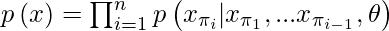
- Für Bilder wählen wir die Identitätspermutation π i = i für 1 ≤ i ≤ n, auch als Rasterreihenfolge bekannt. Das Modell wird trainiert, um die negative Log-Wahrscheinlichkeit zu minimieren:
![L_ {AR} = \ mathbb {E} _ {x \ sim X} \ left [-log \ left (p (x) \ right) \ right]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-20d04adca1c6032b08205c45bd5dcbaa_l3.png)
- Die Autoren verwendeten auch die Verlustfunktion ähnlich der maskierten Sprachmodellierung in BERT, die eine Teilsequenz M ⊂ [1, n] abtastet, so dass jeder Index i unabhängig eine Wahrscheinlichkeit von 0,15 hat, in M zu erscheinen.
![L_ {BERT} = \ mathbb {E} _ {x \ sim X} \ mathbb {E} _ {M} \ left [-log \ left (p (x_i | x _ {[1, n] \ backslash M})) \richtig richtig ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-cd195db2c0eab5c6c4d788983397b74b_l3.png)
- Während des Vortrainings wählen wir eines von L AR oder L BERT aus und minimieren den Verlust gegenüber unserem Datensatz vor dem Training.
Feintuning:
- Zur Feinabstimmung führten die Autoren einen durchschnittlichen Pool n L über die Sequenzdimension durch, um einen d-dimensionalen Vektor von Merkmalen pro Beispiel zu extrahieren und eine Projektion aus der durchschnittlichen Poolschicht zu lernen. Die Autoren verwendeten diese Projektion, um den Kreuzentropieverlust L CLF zu minimieren . Das macht die Gesamtzielfunktion
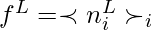
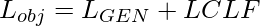
- Wobei L GEN entweder L AR oder L BERT ist .
Die Autoren experimentierten auch mit linearen Sonden, die der Feinabstimmung ähnlich sind, jedoch keine durchschnittliche Pooling-Schicht aufweisen.
Ergebnisse:
- Bei CIFAR-10 erreicht iGPT-L eine Genauigkeit von 99,0% und bei CIFAR-100 nach Feinabstimmung eine Genauigkeit von 88,5%. Das iGPT-L übertrifft AutoAugment, das am besten überwachte Modell für diese Datensätze.
- In ImageNet erreicht iGPT nach Feinabstimmung bei MR (Eingangsauflösung / Speicherauflösung) 32 * 32 eine Genauigkeit von 66,3% , was einer Verbesserung von 6% gegenüber linearer Abtastung entspricht. Bei der Feinabstimmung bei MR 48 * 48 erreichte das Modell eine Genauigkeit von 72,6% mit einer ähnlichen Verbesserung von 7% gegenüber der linearen Abtastung.
Verweise:
