Datenanalyse mit Pandas
Pandas ist die beliebteste Python-Bibliothek, die für die Datenanalyse verwendet wird. Es bietet eine hochoptimierte Leistung, da der Back-End-Quellcode ausschließlich in C oder Python geschrieben ist .
Wir können Daten in Pandas analysieren mit:
- Serie
- DataFrames
Serie:
Serie ist ein eindimensionales (1-D) Array, das in Pandas definiert ist und zum Speichern eines beliebigen Datentyps verwendet werden kann.
Code 1: Serien erstellen
importpandas as pda=pd.Series(Data, index=Index)
Hier können Daten sein:
- Ein skalarer Wert, der integerValue, string sein kann
- Ein Python-Wörterbuch, das ein Schlüssel-Wert-Paar sein kann
- Ein Ndarray
Hinweis : Der Index ist standardmäßig von 0, 1, 2,… (n-1), wobei n die Datenlänge ist.
Code 2: Wenn Daten Skalarwerte enthalten
Data=[1,3,4,5,6,2,9]s=pd.Series(Data)Index=['a','b','c','d','e','f','g']si=pd.Series(Data, Index)
Ausgabe :
Skalardaten mit Standardindex
Skalardaten mit Index


Code 3: Wenn Daten Wörterbuch enthalten
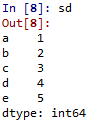
dictionary={'a':1,'b':2,'c':3,'d':4,'e':5}sd=pd.Series(dictionary)
Ausgabe :
Wörterbuchtypdaten
Code 4: Wenn Daten Ndarray enthalten
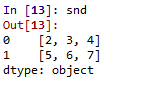
Data=[[2,3,4], [5,6,7]]snd=pd.Series(Data)
Ausgabe :
Daten als Ndarray
DataFrames:
DataFrames ist eine zweidimensionale (2-D) Datenstruktur, die in Pandas definiert ist und aus Zeilen und Spalten besteht.
Code 1: Erstellung von DataFrame
importpandas as pda=pd.DataFrame(Data)
Hier können Daten sein:
- Ein oder mehrere Wörterbücher
- Eine oder mehrere Serien
- 2D-numpy Ndarray
Code 2: Wenn Daten Wörterbücher sind
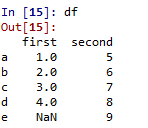
dict1={'a':1,'b':2,'c':3,'d':4}dict2={'a':5,'b':6,'c':7,'d':8,'e':9}Data={'first':dict1,'second':dict2}df=pd.DataFrame(Data)
Ausgabe :
DataFrame mit zwei Wörterbüchern
Code 3: Wenn Daten Serien sind
importpandas as pds1=pd.Series([1,3,4,5,6,2,9])s2=pd.Series([1.1,3.5,4.7,5.8,2.9,9.3])s3=pd.Series(['a','b','c','d','e'])Data={'first':s1,'second':s2,'third':s3}dfseries=pd.DataFrame(Data)
Ausgabe :
DataFrame mit drei Serien

Code 4: Wenn Daten 2D-numpy ndarray sind
Hinweis : Eine Einschränkung muss beim Erstellen des Datenrahmens von 2D-Arrays beibehalten werden - Die Abmessungen des 2D-Arrays müssen gleich sein.
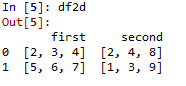
importpandas as pdd1=[[2,3,4], [5,6,7]]d2=[[2,4,8], [1,3,9]]Data={'first': d1,'second': d2}df2d=pd.DataFrame(Data)
Ausgabe :
DataFrame mit 2d ndarray