Empfehlungssystem in Python
Es gibt viele Anwendungen, bei denen Websites Daten von ihren Benutzern sammeln und diese Daten verwenden, um die Vorlieben und Abneigungen ihrer Benutzer vorherzusagen. Auf diese Weise können sie die Inhalte empfehlen, die ihnen gefallen. Empfehlungssysteme sind eine Möglichkeit, Artikel und Ideen für die spezifische Denkweise eines Benutzers vorzuschlagen oder zu ähneln.
Recommender System ist verschiedene Typen:
- Kollaboratives Filtern: Kollaboratives Filtern empfiehlt Elemente basierend auf Ähnlichkeitsmaßen zwischen Benutzern und/oder Elementen. Die Grundannahme hinter dem Algorithmus ist, dass Nutzer mit ähnlichen Interessen gemeinsame Präferenzen haben.
- Inhaltsbasierte Empfehlung: Es handelt sich um überwachtes maschinelles Lernen, das verwendet wird, um einen Klassifikator zu veranlassen, zwischen interessanten und uninteressanten Elementen für den Benutzer zu unterscheiden.
Inhaltsbasiertes Empfehlungssystem: Inhaltsbasierte Systeme empfehlen dem Kunden Artikel ähnlich zu zuvor hoch bewerteten Artikeln durch den Kunden. Es verwendet die Merkmale und Eigenschaften des Elements. Aus diesen Eigenschaften kann es die Ähnlichkeit zwischen den Elementen berechnen.
In einem inhaltsbasierten Empfehlungssystem müssen wir zunächst ein Profil für jeden Artikel erstellen, das die Eigenschaften dieser Artikel darstellt. Aus den Benutzerprofilen wird auf einen bestimmten Benutzer geschlossen. Wir verwenden diese Benutzerprofile, um den Benutzern die Artikel aus dem Katalog zu empfehlen.
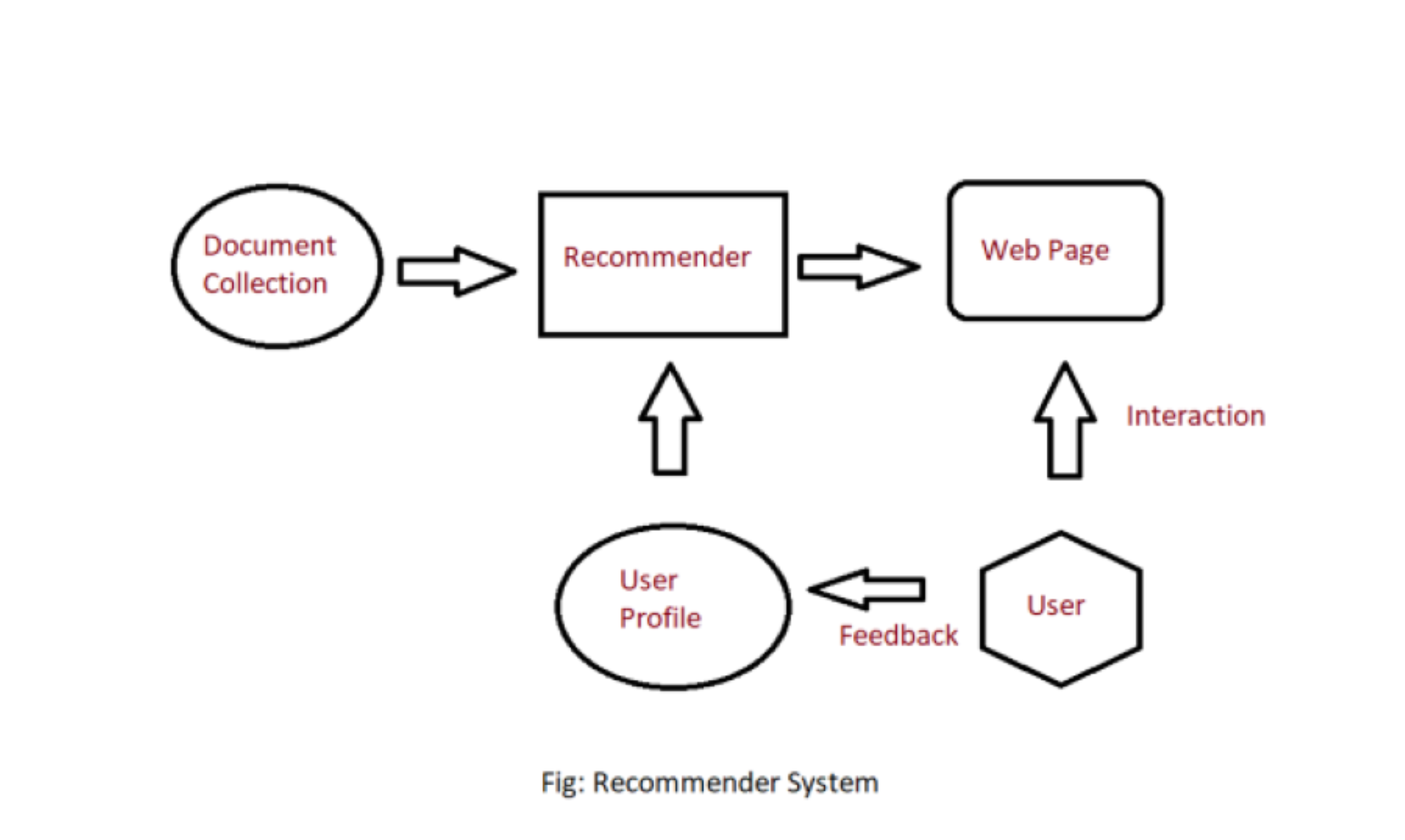
Inhaltsbasiertes Empfehlungssystem
Artikelprofil:
In einem inhaltsbasierten Empfehlungssystem müssen wir für jeden Artikel ein Profil erstellen, das die wichtigen Eigenschaften jedes Artikels enthält. Wenn der Film beispielsweise ein Element ist, dann sind Schauspieler, Regisseur, Veröffentlichungsjahr und Genre seine wichtigen Eigenschaften , und für das Dokument ist die wichtige Eigenschaft der Inhaltstyp und die darin enthaltenen wichtigen Wörter.
Sehen wir uns an, wie Sie ein Artikelprofil erstellen. Zuerst müssen wir den TF-IDF-Vektorisierer durchführen, hier ist die TF (Begriffshäufigkeit) eines Wortes die Häufigkeit, mit der es in einem Dokument vorkommt, und die IDF (inverse Dokumenthäufigkeit) eines Wortes ist das Maß dafür, wie wichtig dieser Begriff ist im ganzen Korpus. Diese lassen sich nach folgender Formel berechnen:
- Die Begriffshäufigkeit kann berechnet werden durch:

wobei f ij die Häufigkeit des Begriffs (Merkmals) i im Dokument (Element) j ist.
- Die Inverse-Document-Häufigkeit lässt sich berechnen mit:

wo, n i Anzahl der Dokumente, die den Begriff i erwähnen . N ist die Gesamtzahl der Dokumente.
- Daher lautet die Gesamtformel:

Hier ist das Dokumentprofil der Satz von Wörtern mit
Benutzerprofil:
Das Benutzerprofil ist ein Vektor, der die Benutzerpräferenz beschreibt. Bei der Erstellung des Benutzerprofils verwenden wir eine Nutzenmatrix, die die Beziehung zwischen Benutzer und Artikel beschreibt. Aus diesen Informationen können wir am besten abschätzen, welcher Artikel dem Benutzer gefällt, indem wir die Profile dieser Artikel aggregieren.
Vorteile und Nachteile:
- Vorteile:
- Keine Notwendigkeit für Daten anderer Benutzer, wenn Sie sich bei ähnlichen Benutzern bewerben.
- Kann Benutzern mit einzigartigem Geschmack empfehlen.
- Kann neue und beliebte Artikel empfehlen
- Erläuterungen zu empfohlenen Artikeln.
- Nachteile :
- Das passende Feature zu finden ist schwierig.
- Empfiehlt keine Artikel außerhalb des Benutzerprofils.
Kollaboratives Filtern: Kollaboratives Filtern basiert auf der Idee, dass ähnliche Personen (basierend auf den Daten) im Allgemeinen dazu neigen, ähnliche Dinge zu mögen. Es sagt voraus, welcher Artikel einem Benutzer gefallen wird, basierend auf den Artikelpräferenzen anderer ähnlicher Benutzer.
Kollaboratives Filtern verwendet eine Benutzerelementmatrix, um Empfehlungen zu generieren. Diese Matrix enthält die Werte, die die Präferenz eines Benutzers gegenüber einem bestimmten Artikel angeben. Diese Werte können entweder explizites Feedback (direkte Nutzerbewertungen) oder implizites Feedback (indirektes Nutzerverhalten wie Zuhören, Kaufen, Anschauen) darstellen.
- Explizites Feedback: Die Datenmenge, die von den Benutzern gesammelt wird, wenn sie sich dafür entscheiden. In vielen Fällen entscheiden sich Benutzer dafür, keine Daten für den Benutzer bereitzustellen. Diese Daten sind also knapp und kosten manchmal Geld. Zum Beispiel Bewertungen vom Benutzer.
- Implizites Feedback: Beim impliziten Feedback verfolgen wir das Benutzerverhalten , um seine Vorlieben vorherzusagen.
Beispiel:
- Stellen Sie sich einen Benutzer x vor, wir müssen einen anderen Benutzer finden, dessen Bewertung der Bewertung von x ähnlich ist, und dann schätzen wir die Bewertung von x basierend auf einem anderen Benutzer.
| M_1 | M_2 | M_3 | M_4 | M_5 | M_6 | M_7 | |
|---|---|---|---|---|---|---|---|
| EIN | 4 | 5 | 1 | ||||
| B | 5 | 5 | 4 | 5 | |||
| C | 2 | 4 | |||||
| D | 3 | 3 |
- Lassen Sie uns eine Matrix erstellen, die verschiedene Benutzer und Filme darstellt:
- Betrachten Sie zwei Benutzer x, y mit Bewertungsvektoren r x und r y . Wir müssen eine Ähnlichkeitsmatrix festlegen, um die Ähnlichkeit b/w sim(x,y) zu berechnen. Es gibt viele Methoden zur Berechnung der Ähnlichkeit, wie z. B.: Jaccard-Ähnlichkeit, Kosinus-Ähnlichkeit und Pearson-Ähnlichkeit. Hier verwenden wir zentrierte Cosinus-Ähnlichkeit/Pearson-Ähnlichkeit, wobei wir die Bewertung normalisieren, indem wir den Mittelwert subtrahieren:
| M_1 | M_2 | M_3 | M_4 | M_5 | M_6 | M_7 | |
|---|---|---|---|---|---|---|---|
| EIN | 2/3 | 5/3 | -7/3 | ||||
| B | 1/3 | 1/3 | -2/3 | ||||
| C | -5/3 | 1/3 | 4/3 | ||||
| D | 0 | 0 |
- Hier können wir die Ähnlichkeit berechnen: Zum Beispiel: sim(A,B) = cos(r A , r B ) = 0,09 ; sim(A,C) = -0,56. sim(A,B) > sim(A,C).
Bewertungsvorhersagen
- Sei r x der Vektor der Bewertung des Benutzers x. Sei N die Menge von k ähnlichen Benutzern, die auch Item i bewertet haben. Dann können wir die Vorhersage von Benutzer x und Artikel i berechnen, indem wir die folgende Formel verwenden:

Vorteile und Nachteile:
- Vorteile:
- Keine Domänenkenntnisse erforderlich, da die Einbettung automatisch erlernt wird.
- Erfassen Sie inhärente subtile Eigenschaften.
- Nachteile :
- Kann aufgrund von Kaltstartproblemen keine frischen Artikel verarbeiten.
- Es ist schwierig, neue Funktionen hinzuzufügen, die die Qualität des Modells verbessern könnten
Implementierung:
Python3
# code
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
ratings = pd.read_csv("https://s3-us-west-2.amazonaws.com/recommender-tutorial/ratings.csv")
ratings.head()
movies = pd.read_csv("https://s3-us-west-2.amazonaws.com/recommender-tutorial/movies.csv")
movies.head()
n_ratings = len(ratings)
n_movies = len(ratings['movieId'].unique())
n_users = len(ratings['userId'].unique())
print(f"Number of ratings: {n_ratings}")
print(f"Number of unique movieId's: {n_movies}")
print(f"Number of unique users: {n_users}")
print(f"Average ratings per user: {round(n_ratings/n_users, 2)}")
print(f"Average ratings per movie: {round(n_ratings/n_movies, 2)}")
user_freq = ratings[['userId', 'movieId']].groupby('userId').count().reset_index()
user_freq.columns = ['userId', 'n_ratings']
user_freq.head()
# Find Lowest and Highest rated movies:
mean_rating = ratings.groupby('movieId')[['rating']].mean()
# Lowest rated movies
lowest_rated = mean_rating['rating'].idxmin()
movies.loc[movies['movieId'] == lowest_rated]
# Highest rated movies
highest_rated = mean_rating['rating'].idxmax()
movies.loc[movies['movieId'] == highest_rated]
# show number of people who rated movies rated movie highest
ratings[ratings['movieId']==highest_rated]
# show number of people who rated movies rated movie lowest
ratings[ratings['movieId']==lowest_rated]
## the above movies has very low dataset. We will use bayesian average
movie_stats = ratings.groupby('movieId')[['rating']].agg(['count', 'mean'])
movie_stats.columns = movie_stats.columns.droplevel()
# Now, we create user-item matrix using scipy csr matrix
from scipy.sparse import csr_matrix
def create_matrix(df):
N = len(df['userId'].unique())
M = len(df['movieId'].unique())
# Map Ids to indices
user_mapper = dict(zip(np.unique(df["userId"]), list(range(N))))
movie_mapper = dict(zip(np.unique(df["movieId"]), list(range(M))))
# Map indices to IDs
user_inv_mapper = dict(zip(list(range(N)), np.unique(df["userId"])))
movie_inv_mapper = dict(zip(list(range(M)), np.unique(df["movieId"])))
user_index = [user_mapper[i] for i in df['userId']]
movie_index = [movie_mapper[i] for i in df['movieId']]
X = csr_matrix((df["rating"], (movie_index, user_index)), shape=(M, N))
return X, user_mapper, movie_mapper, user_inv_mapper, movie_inv_mapper
X, user_mapper, movie_mapper, user_inv_mapper, movie_inv_mapper = create_matrix(ratings)
from sklearn.neighbors import NearestNeighbors
"""
Find similar movies using KNN
"""
def find_similar_movies(movie_id, X, k, metric='cosine', show_distance=False):
neighbour_ids = []
movie_ind = movie_mapper[movie_id]
movie_vec = X[movie_ind]
k+=1
kNN = NearestNeighbors(n_neighbors=k, algorithm="brute", metric=metric)
kNN.fit(X)
movie_vec = movie_vec.reshape(1,-1)
neighbour = kNN.kneighbors(movie_vec, return_distance=show_distance)
for i in range(0,k):
n = neighbour.item(i)
neighbour_ids.append(movie_inv_mapper[n])
neighbour_ids.pop(0)
return neighbour_ids
movie_titles = dict(zip(movies['movieId'], movies['title']))
movie_id = 3
similar_ids = find_similar_movies(movie_id, X, k=10)
movie_title = movie_titles[movie_id]
print(f"Since you watched {movie_title}")
for i in similar_ids:
print(movie_titles[i])
Ausgabe:
Number of ratings: 100836
Number of unique movieId's: 9724
Number of unique users: 610
Average number of ratings per user: 165.3
Average number of ratings per movie: 10.37
==========================================
# lowest rated
movieId title genres
2689 3604 Gypsy (1962) Musical
# highest rated
movieId title genres
48 53 Lamerica (1994) Adventure|Drama
# who rate highest rated movie
userId movieId rating timestamp
13368 85 53 5.0 889468268
96115 603 53 5.0 963180003
# who rate lowest rated movie
userId movieId rating timestamp
13633 89 3604 0.5 1520408880
Since you watched Grumpier Old Men (1995)
Grumpy Old Men (1993)
Striptease (1996)
Nutty Professor, The (1996)
Twister (1996)
Father of the Bride Part II (1995)
Broken Arrow (1996)
Bio-Dome (1996)
Truth About Cats & Dogs, The (1996)
Sabrina (1995)
Birdcage, The (1996