Konvertieren Sie verschachteltes JSON in CSV in Python
In diesem Artikel werden wir erörtern, wie wir verschachteltes JSON in Python in CSV konvertieren können.
Ein Beispiel für eine einfache JSON-Datei:

Eine einfache JSON-Darstellung
Wie Sie im Beispiel sehen können, wird ein einzelnes Schlüsselwertpaar durch einen Doppelpunkt (:) getrennt, während alle Schlüsselwertpaare durch ein Komma (,) getrennt werden. Hier sind „Name“, „Profil“, „Alter“ und „Standort“ die Schlüsselfelder, während die entsprechenden Werte „ Amit Pathak “, „ Software Engineer “, „24“, „London, UK“ lauten.
Ein verschachteltes JSON ist eine Struktur, in der der Wert für ein oder mehrere Felder ein anderes JSON-Format haben kann. Folgen Sie beispielsweise dem folgenden Beispiel, das wir zum Konvertieren in das CSV-Format verwenden werden.
Ein Beispiel für eine verschachtelte JSON-Datei:

Ein verschachteltes JSON-Beispiel
Im obigen Beispiel hat das Schlüsselfeld „ Artikel “ einen Wert, der ein anderes JSON-Format ist. JSON unterstützt mehrere Verschachtelungen, um bei Bedarf komplexe JSON-Dateien zu erstellen.
Verschachtelte JSON-zu-CSV-Konvertierung
Unsere Aufgabe ist es, die JSON-Datei in ein CSV-Format zu konvertieren. Es kann viele Gründe geben, warum wir diese Konvertierung durchführen müssen. CSV sind einfach zu lesen, wenn sie in einer Tabellenkalkulations-GUI-Anwendung wie Google Sheets oder MS Excel geöffnet werden. Sie sind für Datenanalyseaufgaben einfach zu handhaben. Es ist auch ein weithin akzeptiertes Format bei der Arbeit mit tabellarischen Daten, da es im Gegensatz zum JSON-Format für Menschen leicht zu sehen ist.
Sich nähern
- Der erste Schritt besteht darin, die JSON-Datei als Python-Dict-Objekt zu lesen. Dies wird uns helfen, Python-Dict-Methoden zu verwenden, um einige Operationen auszuführen. Für die Aufgabe wird die Funktion read_json() verwendet, die den Dateipfad zusammen mit der Erweiterung als Parameter verwendet und den Inhalt der JSON-Datei als Python-Dict-Objekt zurückgibt.
- Wir normalisieren das dict-Objekt mit der Funktion normalize_json() . Es sucht nach Schlüssel-Wert-Paaren im dict-Objekt. Wenn der Wert wieder ein Diktat ist, wird die Schlüsselzeichenfolge mit der Schlüsselzeichenfolge des verschachtelten Diktats verkettet.
- Die gewünschten CSV-Daten werden mit der Funktion generate_csv_data() erstellt . Diese Funktion verkettet jeden Datensatz mit einem Komma (,) und dann werden alle diese einzelnen Datensätze mit einer neuen Zeile ('\n' in Python) angehängt.
- Im letzten Schritt schreiben wir die im vorherigen Schritt generierten CSV-Daten an einen bevorzugten Speicherort, der durch den filepath- Parameter bereitgestellt wird.
Verwendete Datei: Datei „article.json“.
{
"article_id": 3214507,
"article_link": "http://sample.link",
"published_on": "17-Sep-2020",
"source": "moneycontrol",
"article": {
"title": "IT stocks to see a jump this month",
"category": "finance",
"image": "http://sample.img",
"sentiment": "neutral"
}
}
Beispiel: Konvertieren von JSON in CSV
Python
import json
def read_json(filename: str) -> dict:
try:
with open(filename, "r") as f:
data = json.loads(f.read())
except:
raise Exception(f"Reading {filename} file encountered an error")
return data
def normalize_json(data: dict) -> dict:
new_data = dict()
for key, value in data.items():
if not isinstance(value, dict):
new_data[key] = value
else:
for k, v in value.items():
new_data[key + "_" + k] = v
return new_data
def generate_csv_data(data: dict) -> str:
# Defining CSV columns in a list to maintain
# the order
csv_columns = data.keys()
# Generate the first row of CSV
csv_data = ",".join(csv_columns) + "\n"
# Generate the single record present
new_row = list()
for col in csv_columns:
new_row.append(str(data[col]))
# Concatenate the record with the column information
# in CSV format
csv_data += ",".join(new_row) + "\n"
return csv_data
def write_to_file(data: str, filepath: str) -> bool:
try:
with open(filepath, "w+") as f:
f.write(data)
except:
raise Exception(f"Saving data to {filepath} encountered an error")
def main():
# Read the JSON file as python dictionary
data = read_json(filename="article.json")
# Normalize the nested python dict
new_data = normalize_json(data=data)
# Pretty print the new dict object
print("New dict:", new_data)
# Generate the desired CSV data
csv_data = generate_csv_data(data=new_data)
# Save the generated CSV data to a CSV file
write_to_file(data=csv_data, filepath="data.csv")
if __name__ == '__main__':
main()
Ausgabe:

Python-Konsolenausgabe für Codeblock 1

CSV-Ausgabe für Codeblock 1
Dasselbe kann durch die Verwendung von Pandas Python-Bibliothek erreicht werden. Pandas ist eine kostenlose Python-Quellbibliothek, die zur Datenmanipulation und -analyse verwendet wird. Es führt Operationen aus, indem es die Daten in ein pandas.DataFrame -Format konvertiert. Es bietet viele Funktionalitäten und Operationen, die auf dem Datenrahmen ausgeführt werden können.
Sich nähern
- Der erste Schritt besteht darin, die JSON-Datei als Python-Dict-Objekt zu lesen. Dies wird uns helfen, Python-Dict-Methoden zu verwenden, um einige Operationen auszuführen. Für die Aufgabe wird die Funktion read_json() verwendet, die den Dateipfad zusammen mit der Erweiterung als Parameter verwendet und den Inhalt der JSON-Datei als Python-Dict-Objekt zurückgibt.
- Wir normalisieren das dict-Objekt mit der Funktion normalize_json() . Es sucht nach Schlüssel-Wert-Paaren im dict-Objekt. Wenn der Wert wieder ein Diktat ist, wird die Schlüsselzeichenfolge mit der Schlüsselzeichenfolge des verschachtelten Diktats verkettet.
- In diesem Schritt verwenden wir die Methode pandas.DataFrame() , anstatt manuelle Anstrengungen zu unternehmen, um einzelne Objekte als jeden Datensatz der CSV anzuhängen . Es nimmt das dict-Objekt auf und generiert die gewünschten CSV-Daten in Form des pandas DataFrame-Objekts. Eine Sache im obigen Code ist erwähnenswert, dass die Werte der dict-Variable „ new_data “ in einer Liste vorhanden sind. Der Grund dafür ist, dass beim Übergeben eines Wörterbuchs zum Erstellen eines Pandas-Datenrahmens die Werte des Diktats eine Liste von Werten sein müssen, wobei jeder Wert den Wert darstellt, der in jeder Zeile für diesen Schlüssel- oder Spaltennamen vorhanden ist. Hier haben wir eine einzelne Zeile.
- Wir verwenden die Methode pandas.DataFrame.to_csv() , die den Pfad zusammen mit dem Dateinamen, in dem Sie die CSV speichern möchten, als Eingabeparameter übernimmt und die generierten CSV-Daten in Schritt 3 als CSV speichert.
Beispiel: Konvertierung von JSON in CSV mit Pandas
Python
import json
import pandas
def read_json(filename: str) -> dict:
try:
with open(filename, "r") as f:
data = json.loads(f.read())
except:
raise Exception(f"Reading {filename} file encountered an error")
return data
def normalize_json(data: dict) -> dict:
new_data = dict()
for key, value in data.items():
if not isinstance(value, dict):
new_data[key] = value
else:
for k, v in value.items():
new_data[key + "_" + k] = v
return new_data
def main():
# Read the JSON file as python dictionary
data = read_json(filename="article.json")
# Normalize the nested python dict
new_data = normalize_json(data=data)
print("New dict:", new_data, "\n")
# Create a pandas dataframe
dataframe = pandas.DataFrame(new_data, index=[0])
# Write to a CSV file
dataframe.to_csv("article.csv")
if __name__ == '__main__':
main()
Ausgabe:

Python-Konsolenausgabe für Codeblock 2
CSV-Ausgabe für Codeblock 2
Die beiden obigen Beispiele sind gut, wenn wir eine einzige Verschachtelungsebene für JSON haben, aber wenn die Verschachtelung zunimmt und mehr Datensätze vorhanden sind, erfordern die obigen Codes mehr Bearbeitung. Wir können solche JSON-Dateien mit der Pandas-Bibliothek sehr einfach handhaben. Lassen Sie uns sehen, wie.
Konvertieren Sie N-verschachteltes JSON in CSV
Eine beliebige Anzahl von Verschachtelungen und Datensätzen in einem JSON kann mit minimalem Code mithilfe der Methode „ json_normalize() “ in Pandas verarbeitet werden .
Syntax:
json_normalize(daten)
Verwendete Datei : details.json-Datei
{
"details": [
{
"id": "STU001",
"name": "Amit Pathak",
"age": 24,
"results": {
"school": 85,
"high_school": 75,
"graduation": 70
},
"education": {
"graduation": {
"major": "Computers",
"minor": "Sociology"
}
}
},
{
"id": "STU002",
"name": "Yash Kotian",
"age": 32,
"results": {
"school": 80,
"high_school": 58,
"graduation": 49
},
"education": {
"graduation": {
"major": "Biology",
"minor": "Chemistry"
}
}
},
{
"id": "STU003",
"name": "Aanchal Singh",
"age": 28,
"results": {
"school": 90,
"high_school": 70,
"graduation":65
},
"education": {
"graduation": {
"major": "Art",
"minor": "IT"
}
}
},
{
"id": "STU004",
"name": "Juhi Vadia",
"age": 23,
"results": {
"school": 95,
"high_school": 89,
"graduation": 83
},
"education": {
"graduation": {
"major": "IT",
"minor": "Social"
}
}
}
]
}
Hier besteht der Schlüssel „ Details “ aus einem Array von 4 Elementen, wobei jedes Element 3 Ebenen verschachtelter JSON- Objekte enthält. Die „ Dur “- und „ Moll “-Tonart in jedem dieser Objekte befindet sich in einer Ebene-3-Verschachtelung.
Sich nähern
- Der erste Schritt besteht darin, die JSON-Datei als Python-Dict-Objekt zu lesen. Dies wird uns helfen, Python-Dict-Methoden zu verwenden, um einige Operationen auszuführen. Für die Aufgabe wird die Funktion read_json() verwendet, die den Dateipfad zusammen mit der Erweiterung als Parameter verwendet und den Inhalt der JSON-Datei als Python-Dict-Objekt zurückgibt.
- Wir haben für jedes im Details-Array vorhandene JSON-Objekt iteriert. In jeder Iteration haben wir zuerst den JSON normalisiert und einen temporären Datenrahmen erstellt. Dieser Datenrahmen wurde dann an den Ausgabedatenrahmen angehängt.
- Anschließend wurde der Spaltenname zur besseren Sichtbarkeit umbenannt. Wenn wir die Konsolenausgabe sehen, wurde die Spalte „ major “ vor der Umbenennung als „ education.graduation.major “ benannt. Dies liegt daran, dass die Methode „ json_normalize() “ die Schlüssel in der vollständigen Verschachtelung zum Generieren des Spaltennamens verwendet, um Probleme mit doppelten Spalten zu vermeiden. „ Bildung “ ist also die erste Ebene, „ Abschluss “ die zweite und „ Hauptfach “ die dritte Ebene in der JSON-Verschachtelung. Daher wurde die Spalte „ Bildung.Abschluss.Major “ einfach in „Abschluss“ umbenannt.
- Nach dem Umbenennen der Spalten speichert die Methode to_csv() das Pandas-Datenrahmenobjekt als CSV am angegebenen Dateispeicherort.
Beispiel: Konvertieren von n-verschachteltem JSON in CSV
Python
import json
import pandas
def read_json(filename: str) -> dict:
try:
with open(filename, "r") as f:
data = json.loads(f.read())
except:
raise Exception(f"Reading {filename} file encountered an error")
return data
def create_dataframe(data: list) -> pandas.DataFrame:
# Declare an empty dataframe to append records
dataframe = pandas.DataFrame()
# Looping through each record
for d in data:
# Normalize the column levels
record = pandas.json_normalize(d)
# Append it to the dataframe
dataframe = dataframe.append(record, ignore_index=True)
return dataframe
def main():
# Read the JSON file as python dictionary
data = read_json(filename="details.json")
# Generate the dataframe for the array items in
# details key
dataframe = create_dataframe(data=data['details'])
# Renaming columns of the dataframe
print("Normalized Columns:", dataframe.columns.to_list())
dataframe.rename(columns={
"results.school": "school",
"results.high_school": "high_school",
"results.graduation": "graduation",
"education.graduation.major": "grad_major",
"education.graduation.minor": "grad_minor"
}, inplace=True)
print("Renamed Columns:", dataframe.columns.to_list())
# Convert dataframe to CSV
dataframe.to_csv("details.csv", index=False)
if __name__ == '__main__':
main()
Ausgabe:
$Konsolenausgabe
—–
Normalisierte Spalten: ['id', 'name', 'age', 'results.school', 'results.high_school', 'results.graduation', 'education.graduation.major', 'education.graduation.minor']
Umbenannte Spalten: ['id', 'name', 'age', 'school', 'high_school', 'graduation', 'grad_major', 'grad_minor']
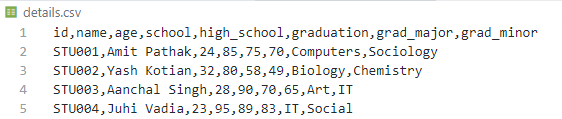
CSV-Ausgabe für Codeblock 3