ML | Unüberwachte Face Clustering Pipeline
Die Live-Gesichtserkennung ist ein Problem, mit dem die automatisierte Sicherheitsabteilung immer noch konfrontiert ist. Mit den Fortschritten bei Convolutions Neural Networks und speziell kreativen Methoden von Region-CNN wurde bereits bestätigt, dass wir uns mit unseren aktuellen Technologien für überwachte Lernoptionen wie FaceNet, YOLO für eine schnelle und lebendige Gesichtserkennung in einer realen Umgebung entscheiden können .
Um ein überwachtes Modell zu trainieren, müssen wir Datensätze unserer Zieletiketten abrufen, was immer noch eine mühsame Aufgabe ist. Wir benötigen eine effiziente und automatisierte Lösung für die Datensatzgenerierung mit minimalem Etikettierungsaufwand durch Benutzereingriffe.
Vorgeschlagene Lösung -
Einführung: Wir schlagen eine Pipeline zur Generierung von Datensätzen vor, die einen Videoclip als Quelle verwendet, alle Gesichter extrahiert und zu begrenzten und genauen Bildsätzen gruppiert, die eine bestimmte Person darstellen. Jeder Satz kann leicht durch menschliche Eingaben mit Leichtigkeit beschriftet werden.
Technische Details: Wir werden opencv lib für die Extraktion von Bildern pro Sekunde aus dem eingegebenen Videoclip verwenden. 1 Sekunde erscheint angemessen, um relevante Daten und begrenzte Frames für die Verarbeitung abzudecken.
Wir werden die face_recognition Bibliothek (unterstützt von dlib) verwenden, um die Flächen aus den Rahmen zu extrahieren und sie für Feature-Extraktionen auszurichten.
Anschließend extrahieren wir die vom Menschen beobachtbaren Merkmale und gruppieren sie mithilfe des von scikit-learn bereitgestellten DBSCAN-Clusters .
Für die Lösung werden alle Gesichter ausgeschnitten, Beschriftungen erstellt und in Ordnern gruppiert, damit Benutzer sie als Datensatz für ihre Schulungsanwendungsfälle anpassen können.
Herausforderungen bei der Implementierung: Für ein größeres Publikum planen wir, die Lösung für die Ausführung in einer CPU anstelle einer NVIDIA-GPU zu implementieren. Die Verwendung einer NVIDIA-GPU kann die Effizienz der Pipeline erhöhen.
Die CPU-Implementierung der Gesichtseinbettungsextraktion ist sehr langsam (30+ Sekunden pro Bild). Um das Problem zu lösen, implementieren wir sie mit parallelen Pipeline-Ausführungen (was ~ 13 Sekunden pro Bild ergibt) und führen ihre Ergebnisse später für weitere Clustering-Aufgaben zusammen. Wir führen tqdm zusammen mit PyPiper Fortschrittsaktualisierungen und die Größenänderung von Frames ein, die aus dem Eingangsvideo extrahiert wurden, um eine reibungslose Ausführung der Pipeline zu gewährleisten.
Eingabe: Footage.mp4 Ausgabe: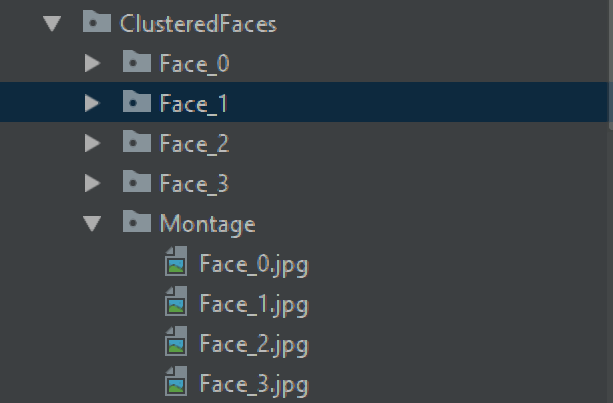
Erforderliche Python3-Module:
os, cv2, numpy, tensorflow, json, re, shutil, time, pickle, pyPiper, tqdm, imutils, face_recognition, dlib, warnings, sklearn
Abschnitt "Snippets":
Für den Inhalt der Datei FaceClusteringLibrary.py, die alle Klassendefinitionen enthält, folgen die Snippets und Erläuterungen zu deren Funktionsweise.
Klassenimplementierung von ResizeUtilsbietet Funktion rescale_by_height und rescale_by_width.
"Rescale_by_width" ist eine Funktion, die 'image' und 'target_width' als Eingabe verwendet. Es skaliert / verkleinert die Bildabmessung für die Breite, um die zu erfüllen target_width. Die Höhe wird automatisch berechnet, damit das Seitenverhältnis gleich bleibt. rescale_by_height ist auch das gleiche, aber anstelle der Breite wird die Höhe angestrebt.
classResizeUtils:defrescale_by_height(self, image, target_height,method=cv2.INTER_LANCZOS4):w=int(round(target_height*image.shape[1]/image.shape[0]))return(cv2.resize(image, (w, target_height),interpolation=method))defrescale_by_width(self, image, target_width,method=cv2.INTER_LANCZOS4):h=int(round(target_width*image.shape[0]/image.shape[1]))return(cv2.resize(image, (target_width, h),interpolation=method))
Es folgt die Definition der FramesGeneratorKlasse. Diese Klasse bietet Funktionen zum Extrahieren von JPG-Bildern durch sequentielles Lesen des Videos. Wenn wir ein Beispiel für eine Eingangsvideodatei nehmen, kann diese eine Bildrate von ~ 30 fps haben. Wir können daraus schließen, dass es für 1 Sekunde Video 30 Bilder gibt. Selbst für ein 2-minütiges Video beträgt die Anzahl der zu verarbeitenden Bilder 2 * 60 * 30 = 3600. Die Verarbeitung der Bilder ist zu hoch und die vollständige Pipeline-Verarbeitung kann Stunden dauern.
Aber es kommt noch eine Tatsache, dass sich Gesichter und Menschen nicht innerhalb einer Sekunde ändern können. Wenn man also ein 2-minütiges Video betrachtet, ist das Generieren von 30 Bildern für 1 Sekunde umständlich und wiederholt. Stattdessen können wir nur 1 Bildausschnitt in 1 Sekunde aufnehmen. Bei der Implementierung von „FramesGenerator“ wird nur 1 Bild pro Sekunde aus einem Videoclip ausgegeben.
In Anbetracht der Tatsache, dass die gedumpten Bilder face_recognition/dlibfür die Gesichtsextraktion verarbeitet werden, versuchen wir, einen Schwellenwert für die Höhe von nicht mehr als 500 und die Breite auf 700 zu beschränken. Diese Begrenzung wird durch die Funktion "AutoResize" festgelegt, die weitere Aufrufe vornimmt rescale_by_height oder rescale_by_width deren Größe verringert Das Bild, wenn Grenzwerte erreicht werden, das Seitenverhältnis jedoch beibehalten wird.
Beim folgenden Snippet AutoResize versucht die Funktion, die Dimension eines bestimmten Bildes zu begrenzen. Wenn die Breite größer als 700 ist, verkleinern wir sie, um die Breite 700 beizubehalten und das Seitenverhältnis beizubehalten. Eine weitere hier festgelegte Grenze ist, dass die Höhe nicht größer als 500 sein darf.
classFramesGenerator:def__init__(self, VideoFootageSource):self.VideoFootageSource=VideoFootageSourcedefAutoResize(self, frame):resizeUtils=ResizeUtils()height, width, _=frame.shapeifheight >500:frame=resizeUtils.rescale_by_height(frame,500)self.AutoResize(frame)ifwidth >700:frame=resizeUtils.rescale_by_width(frame,700)self.AutoResize(frame)returnframe
Es folgt das Snippet für die GenerateFramesFunktion. Es fragt die fps ab, um zu entscheiden, unter wie vielen Frames 1 Bild ausgegeben werden kann. Wir löschen das Ausgabeverzeichnis und beginnen mit der Iteration durch die Frames. Bevor wir ein Bild sichern, ändern wir die Größe des Bildes, wenn es den in der AutoResize Funktion angegebenen Grenzwert erreicht .
defGenerateFrames(self, OutputDirectoryName):cap=cv2.VideoCapture(self.VideoFootageSource)_, frame=cap.read()fps=cap.get(cv2.CAP_PROP_FPS)TotalFrames=cap.get(cv2.CAP_PROP_FRAME_COUNT)("[INFO] Total Frames ", TotalFrames," @ ", fps," fps")("[INFO] Calculating number of frames per second")CurrentDirectory=os.path.curdirOutputDirectoryPath=os.path.join(CurrentDirectory, OutputDirectoryName)ifos.path.exists(OutputDirectoryPath):shutil.rmtree(OutputDirectoryPath)time.sleep(0.5)os.mkdir(OutputDirectoryPath)CurrentFrame=1fpsCounter=0FrameWrittenCount=1whileCurrentFrame < TotalFrames:_, frame=cap.read()if(frameisNone):continueiffpsCounter > fps:fpsCounter=0frame=self.AutoResize(frame)filename="frame_"+str(FrameWrittenCount)+".jpg"cv2.imwrite(os.path.join(OutputDirectoryPath, filename), frame)FrameWrittenCount+=1fpsCounter+=1CurrentFrame+=1('[INFO] Frames extracted')
Es folgt der Ausschnitt für die FramesProviderKlasse. Es erbt "Node", mit dem die Bildverarbeitungspipeline erstellt werden kann. Wir implementieren "Setup" - und "Run" -Funktionen. Alle in der Funktion "setup" definierten Argumente können die Parameter enthalten, die vom Konstruktor zum Zeitpunkt der Objekterstellung als Parameter erwartet werden. Hier können wir sourcePath Parameter an das FramesProvider Objekt übergeben. Die Setup-Funktion wird nur einmal ausgeführt. Die Funktion "Ausführen" wird ausgeführt und gibt weiterhin Daten aus, indem die emit Funktion zur Verarbeitung der Pipeline close aufgerufen wird, bis die Funktion aufgerufen wird.
Hier, im "Setup", akzeptieren wir sourcePath als Argument und durchlaufen alle Dateien im angegebenen Frames-Verzeichnis. Unabhängig von der Dateierweiterung .jpg(die von der Klasse generiert wird FrameGenerator) fügen wir sie der Liste "filesList" hinzu.
Während der run Funktionsaufrufe werden alle JPG-Bildpfade aus "filesList" mit Attributen gepackt, die die eindeutige "id" und "imagePath" als Objekt angeben, und zur Verarbeitung an die Pipeline ausgegeben.
classFramesProvider(Node):defsetup(self, sourcePath):self.sourcePath=sourcePathself.filesList=[]foriteminos.listdir(self.sourcePath):_, fileExt=os.path.splitext(item)iffileExt=='.jpg':self.filesList.append(os.path.join(item))self.TotalFilesCount=self.size=len(self.filesList)self.ProcessedFilesCount=self.pos=0defrun(self, data):ifself.ProcessedFilesCount <self.TotalFilesCount:self.emit({'id':self.ProcessedFilesCount,'imagePath': os.path.join(self.sourcePath,self.filesList[self.ProcessedFilesCount])})self.ProcessedFilesCount+=1self.pos=self.ProcessedFilesCountelse:self.close()
Es folgt die Klassenimplementierung von " FaceEncoder ", die "Node" erbt und in die Bildverarbeitungspipeline übertragen werden kann. In der Funktion "Setup" akzeptieren wir den Wert "Detection_Method" für den Aufruf der Gesichtserkennung "face_recognition / dlib". Es kann einen Detektor auf CNN-Basis oder einen Detektor auf Schweinebasis haben.
Die Funktion "Ausführen" entpackt die eingehenden Daten in "ID" und "ImagePath".
Anschließend liest es das Bild aus "imagePath" und führt die in der Bibliothek "face_recognition / dlib" definierte "face_location" aus, um das ausgerichtete Gesichtsbild auszuschneiden, das unsere Region von Interesse ist. Ein ausgerichtetes Gesichtsbild ist ein rechteckiges zugeschnittenes Bild, bei dem Augen und Lippen an einer bestimmten Stelle im Bild ausgerichtet sind (Hinweis: Die Implementierung kann bei anderen Bibliotheken, z. B. opencv, abweichen).
Außerdem rufen wir die in "face_recognition / dlib" definierte Funktion "face_encodings" auf, um die Gesichtseinbettungen aus jeder Box zu extrahieren. Durch diese eingebetteten schwebenden Werte können Sie die genaue Position von Features in einem ausgerichteten Gesichtsbild erreichen.
Wir definieren die Variable "d" als ein Array von Feldern und entsprechenden Einbettungen. Jetzt packen wir die "ID" und das Array von Einbettungen als "Codierungsschlüssel" in ein Objekt und senden es an die Bildverarbeitungspipeline.
classFaceEncoder(Node):defsetup(self, detection_method='cnn'):self.detection_method=detection_methoddefrun(self, data):id=data['id']imagePath=data['imagePath']image=cv2.imread(imagePath)rgb=cv2.cvtColor(image, cv2.COLOR_BGR2RGB)boxes=face_recognition.face_locations(rgb, model=self.detection_method)encodings=face_recognition.face_encodings(rgb, boxes)d=[{"imagePath": imagePath,"loc": box,"encoding": enc}for(box, enc)inzip(boxes, encodings)]self.emit({'id':id,'encodings': d})
Es folgt eine Implementierung, DatastoreManagerdie wiederum von "Node" erbt und in die Bildverarbeitungspipeline eingesteckt werden kann. Das Ziel der Klasse besteht darin, das Array "encodings" als Pickle-Datei zu sichern und die Pickle-Datei mit dem Parameter "id" eindeutig zu benennen. Wir möchten, dass die Pipeline Multithreading ausführt.
Um das Multithreading zur Leistungsverbesserung zu nutzen, müssen wir die asynchronen Aufgaben ordnungsgemäß trennen und versuchen, die Notwendigkeit einer Synchronisierung zu vermeiden. Um eine maximale Leistung zu erzielen, lassen wir die Threads in der Pipeline die Daten unabhängig voneinander in eine einzelne separate Datei schreiben, ohne andere Thread-Vorgänge zu stören.
Wenn Sie sich überlegen, wie viel Zeit in der verwendeten Entwicklungshardware ohne Multithreading gespart wurde, betrug die durchschnittliche Extraktionszeit für das Einbetten ~ 30 Sekunden. Nach der Multithread-Pipeline (mit 4 Threads) verringerte sie sich auf ~ 10 Sekunden, jedoch mit den Kosten einer hohen CPU-Auslastung.
Da der Thread ungefähr 10 Sekunden dauert, treten keine häufigen Schreibvorgänge auf und beeinträchtigen unsere Multithread-Leistung nicht.
Ein anderer Fall, wenn Sie darüber nachdenken, warum Gurke anstelle von JSON-Alternative verwendet wird? Die Wahrheit ist, dass JSON eine bessere Alternative zu Gurke ist. Pickle ist für die Speicherung und Kommunikation von Daten sehr unsicher. Pickles können böswillig geändert werden, um ausführbare Codes in Python einzubetten. Die JSON-Dateien sind für Menschen lesbar und können schneller codiert und decodiert werden. Das einzige, was pickle gut kann, ist das fehlerfreie Ablegen von Python-Objekten und -Inhalten in Binärdateien.
Da wir nicht planen, die Pickle-Dateien zu speichern und zu verteilen und für eine fehlerfreie Ausführung, verwenden wir Pickle. Andernfalls werden JSON und andere Alternativen dringend empfohlen.
classDatastoreManager(Node):defsetup(self, encodingsOutputPath):self.encodingsOutputPath=encodingsOutputPathdefrun(self, data):encodings=data['encodings']id=data['id']withopen(os.path.join(self.encodingsOutputPath,'encodings_'+str(id)+'.pickle'),'wb') as f:f.write(pickle.dumps(encodings))
Es folgt die Implementierung der Klasse PickleListCollator. Es wurde entwickelt, um Arrays von Objekten in mehreren Pickle-Dateien zu lesen, zu einem Array zusammenzuführen und das kombinierte Array in eine einzelne Pickle-Datei zu kopieren.
Hier gibt es nur eine Funktion, GeneratePickle die akzeptiert, outputFilepath die die einzelne Ausgabe-Pickle-Datei angibt, die das zusammengeführte Array enthält.
classPicklesListCollator:def__init__(self, picklesInputDirectory):self.picklesInputDirectory=picklesInputDirectorydefGeneratePickle(self, outputFilepath):datastore=[]ListOfPickleFiles=[]foriteminos.listdir(self.picklesInputDirectory):_, fileExt=os.path.splitext(item)iffileExt=='.pickle':ListOfPickleFiles.append(os.path.join(self.picklesInputDirectory, item))forpicklePathinListOfPickleFiles:withopen(picklePath,"rb") as f:data=pickle.loads(f.read())datastore.extend(data)withopen(outputFilepath,'wb') as f:f.write(pickle.dumps(datastore))
Das Folgende ist die Implementierung der FaceClusterUtilityKlasse. Es ist ein Konstruktor definiert, der "EncodingFilePath" mit Wert als Pfad zur zusammengeführten Pickle-Datei verwendet. Wir lesen das Array aus der Pickle-Datei und versuchen, sie mithilfe der DBSCAN-Implementierung in der Scikit-Bibliothek zu gruppieren. Im Gegensatz zu k-means erfordert der DBSCAN-Scan nicht die Anzahl der Cluster. Die Anzahl der Cluster hängt vom Schwellenwertparameter ab und wird automatisch berechnet.
Die DBSCAN-Implementierung wird in "scikit" bereitgestellt und akzeptiert auch die Anzahl der Threads für die Berechnung.
Hier haben wir eine Funktion "Cluster", die aufgerufen wird, um die Array-Daten aus der Pickle-Datei zu lesen, "DBSCAN" auszuführen, die eindeutigen Cluster als eindeutige Flächen zu drucken und die Beschriftungen zurückzugeben. Die Beschriftungen sind eindeutige Werte, die Kategorien darstellen, mit denen die Kategorie für ein im Array vorhandenes Gesicht identifiziert werden kann. (Der Array-Inhalt stammt aus der Pickle-Datei).
classFaceClusterUtility:def__init__(self, EncodingFilePath):self.EncodingFilePath=EncodingFilePathdefCluster(self):InputEncodingFile=self.EncodingFilePathifnot(os.path.isfile(InputEncodingFile)andos.access(InputEncodingFile, os.R_OK)):('The input encoding file, '+str(InputEncodingFile)+' does not exists or unreadable')exit()NumberOfParallelJobs=-1("[INFO] Loading encodings")data=pickle.loads(open(InputEncodingFile,"rb").read())data=np.array(data)encodings=[d["encoding"]fordindata]("[INFO] Clustering")clt=DBSCAN(eps=0.5, metric="euclidean",n_jobs=NumberOfParallelJobs)clt.fit(encodings)labelIDs=np.unique(clt.labels_)numUniqueFaces=len(np.where(labelIDs >-1)[0])("[INFO] # unique faces: {}".format(numUniqueFaces))returnclt.labels_
Es folgt die Implementierung einer TqdmUpdateKlasse, die von "tqdm" erbt. tqdm ist eine Python-Bibliothek, die einen Fortschrittsbalken in der Konsolenoberfläche anzeigt.
Die Variablen "n" und "total" werden von "tqdm" erkannt. Die Werte dieser beiden Variablen werden verwendet, um den erzielten Fortschritt zu berechnen.
Die Parameter "done" und "total_size" in der Funktion "update" werden als Werte angegeben, wenn sie an das Aktualisierungsereignis im Pipeline-Framework "PyPiper" gebunden sind. Das super().refresh()ruft die Implementierung der Funktion "Aktualisieren" in der Klasse "tqdm" auf, die den Fortschrittsbalken in der Konsole visualisiert und aktualisiert.
classTqdmUpdate(tqdm):defupdate(self, done, total_size=None):iftotal_sizeisnotNone:self.total=total_sizeself.n=donesuper().refresh()
Es folgt die Implementierung der FaceImageGeneratorKlasse. Diese Klasse bietet Funktionen zum Generieren einer Montage, eines zugeschnittenen Porträtbilds und einer Anmerkung für zukünftige Schulungszwecke (z. B. Darknet YOLO) aus den Beschriftungen, die sich nach dem Clustering ergeben.
Der Konstruktor erwartet EncodingFilePath als zusammengeführten Pickle-Dateipfad. Es wird verwendet, um alle Gesichtscodierungen zu laden. Wir interessieren uns jetzt für den „imagePath“ und die Gesichtskoordinaten zur Erzeugung des Bildes.
Der Aufruf von "GenerateImages" erledigt den beabsichtigten Job. Wir laden das Array aus der zusammengeführten Pickle-Datei. Wir wenden die eindeutige Operation auf Etiketten an und durchlaufen die Etiketten. Innerhalb der Iteration der Beschriftungen listen wir für jede eindeutige Beschriftung alle Array-Indizes mit derselben aktuellen Beschriftung auf.
Diese Array-Indizes werden erneut iteriert, um jede Fläche zu verarbeiten.
Für die Gesichtsverarbeitung verwenden wir den Index, um den Pfad für die Bilddatei und die Koordinaten des Gesichts zu erhalten.
Die Bilddatei wird aus dem Pfad der Bilddatei geladen. Die Koordinaten des Gesichts werden zu einer Porträtform erweitert (und wir stellen außerdem sicher, dass es nicht mehr als die Abmessungen des Bildes erweitert) und es wird zugeschnitten und als Porträtbild in eine Datei kopiert.
Wir beginnen erneut mit den ursprünglichen Koordinaten und erweitern sie ein wenig, um Anmerkungen für zukünftige überwachte Schulungsoptionen für verbesserte Erkennungsfähigkeiten zu erstellen.
Zur Annotation haben wir es nur für „Darknet YOLO“ entworfen, aber es kann auch für jedes andere Framework angepasst werden. Schließlich erstellen wir eine Montage und schreiben sie in eine Bilddatei.
classFaceImageGenerator:def__init__(self, EncodingFilePath):self.EncodingFilePath=EncodingFilePathdefGenerateImages(self, labels, OutputFolderName="ClusteredFaces",MontageOutputFolder="Montage"):output_directory=os.getcwd()OutputFolder=os.path.join(output_directory, OutputFolderName)ifnotos.path.exists(OutputFolder):os.makedirs(OutputFolder)else:shutil.rmtree(OutputFolder)time.sleep(0.5)os.makedirs(OutputFolder)MontageFolderPath=os.path.join(OutputFolder, MontageOutputFolder)os.makedirs(MontageFolderPath)data=pickle.loads(open(self.EncodingFilePath,"rb").read())data=np.array(data)labelIDs=np.unique(labels)forlabelIDinlabelIDs:("[INFO] faces for face ID: {}".format(labelID))FaceFolder=os.path.join(OutputFolder,"Face_"+str(labelID))os.makedirs(FaceFolder)idxs=np.where(labels==labelID)[0]portraits=[]counter=1foriinidxs:image=cv2.imread(data[i]["imagePath"])(o_top, o_right, o_bottom, o_left)=data[i]["loc"]height, width, channel=image.shapewidthMargin=100heightMargin=150top=o_top-heightMarginiftop <0: top=0bottom=o_bottom+heightMarginifbottom > height: bottom=heightleft=o_left-widthMarginifleft <0: left=0right=o_right+widthMarginifright > width: right=widthportrait=image[top:bottom, left:right]iflen(portraits) <25:portraits.append(portrait)resizeUtils=ResizeUtils()portrait=resizeUtils.rescale_by_width(portrait,400)FaceFilename="face_"+str(counter)+".jpg"FaceImagePath=os.path.join(FaceFolder, FaceFilename)cv2.imwrite(FaceImagePath, portrait)widthMargin=20heightMargin=20top=o_top-heightMarginiftop <0: top=0bottom=o_bottom+heightMarginifbottom > height: bottom=heightleft=o_left-widthMarginifleft <0: left=0right=o_right+widthMarginifright > width:right=widthAnnotationFilename="face_"+str(counter)+".txt"AnnotationFilePath=os.path.join(FaceFolder, AnnotationFilename)f=open(AnnotationFilePath,'w')f.write(str(labelID)+' '+str(left)+' '+str(top)+' '+str(right)+' '+str(bottom)+"\n")f.close()counter+=1montage=build_montages(portraits, (96,120), (5,5))[0]MontageFilenamePath=os.path.join(MontageFolderPath,"Face_"+str(labelID)+".jpg")cv2.imwrite(MontageFilenamePath, montage)
Speichern Sie die Datei unter FaceClusteringLibrary.py, die alle Klassendefinitionen enthält.
Es folgt eine Datei Driver.py, die die Funktionen zum Erstellen einer Pipeline aufruft.
fromFaceClusteringLibraryimport*if__name__=="__main__":framesGenerator=FramesGenerator("Footage.mp4")framesGenerator.GenerateFrames("Frames")CurrentPath=os.getcwd()FramesDirectory="Frames"FramesDirectoryPath=os.path.join(CurrentPath, FramesDirectory)EncodingsFolder="Encodings"EncodingsFolderPath=os.path.join(CurrentPath, EncodingsFolder)ifos.path.exists(EncodingsFolderPath):shutil.rmtree(EncodingsFolderPath, ignore_errors=True)time.sleep(0.5)os.makedirs(EncodingsFolderPath)pipeline=Pipeline(FramesProvider("Files source", sourcePath=FramesDirectoryPath) |FaceEncoder("Encode faces") |DatastoreManager("Store encoding",encodingsOutputPath=EncodingsFolderPath),n_threads=3, quiet=True)pbar=TqdmUpdate()pipeline.run(update_callback=pbar.update)()('[INFO] Encodings extracted')CurrentPath=os.getcwd()EncodingsInputDirectory="Encodings"EncodingsInputDirectoryPath=os.path.join(CurrentPath, EncodingsInputDirectory)OutputEncodingPickleFilename="encodings.pickle"ifos.path.exists(OutputEncodingPickleFilename):os.remove(OutputEncodingPickleFilename)picklesListCollator=PicklesListCollator(EncodingsInputDirectoryPath)picklesListCollator.GeneratePickle(OutputEncodingPickleFilename)time.sleep(0.5)EncodingPickleFilePath="encodings.pickle"faceClusterUtility=FaceClusterUtility(EncodingPickleFilePath)faceImageGenerator=FaceImageGenerator(EncodingPickleFilePath)labelIDs=faceClusterUtility.Cluster()faceImageGenerator.GenerateImages(labelIDs,"ClusteredFaces","Montage")
Montage Ausgabe:
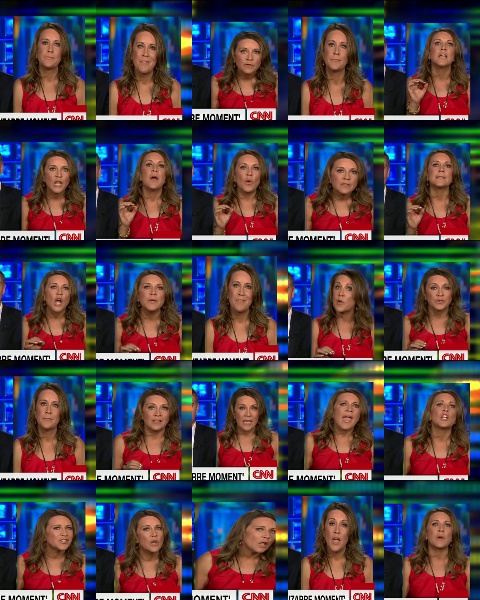
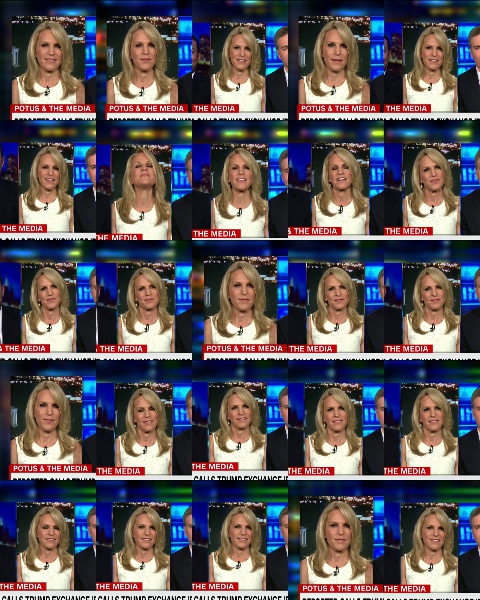

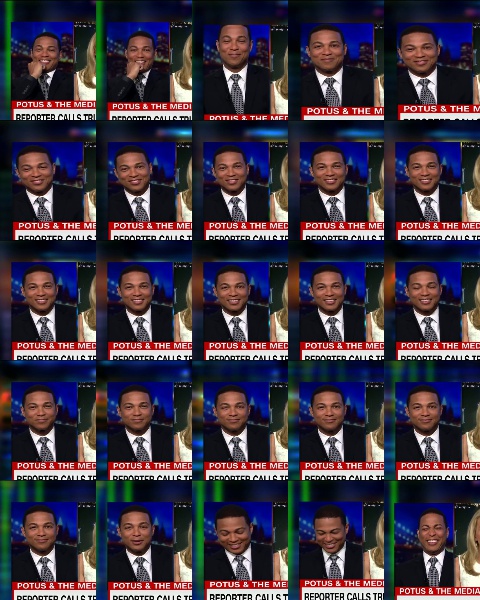
Fehlerbehebung -
Frage 1: Der gesamte PC friert beim Extrahieren der Gesichtseinbettung ein.
Lösung: Die Lösung besteht darin, die Werte in der Frame-Größenänderungsfunktion zu verringern, wenn Frames aus einem eingegebenen Videoclip extrahiert werden. Denken Sie daran, dass ein zu starkes Verringern der Werte zu einer falschen Gesichtsclusterung führt. Anstatt die Größe des Rahmens zu ändern, können wir eine Frontalflächenerkennung einführen und die Frontalflächen nur zur Verbesserung der Genauigkeit ausschneiden.
Frage 2: Der PC wird langsam, während die Pipeline ausgeführt wird.
Lösung: Die CPU wird maximal ausgelastet. Um die Verwendung zu begrenzen, können Sie die Anzahl der im Pipeline-Konstruktor angegebenen Threads verringern.
Frage 3: Das Ausgabe-Clustering ist zu ungenau.
Lösung: Der einzige Grund für den Fall kann sein, dass die aus dem eingegebenen Videoclip extrahierten Bilder sehr Gesichter mit einer sehr geringen Auflösung haben oder die Anzahl der Bilder sehr gering ist (ca. 7-8). Holen Sie sich bitte einen Videoclip mit hellen und klaren Bildern von Gesichtern oder für den letzteren Fall ein 2-minütiges Video oder einen Mod mit Quellcode für die Extraktion von Videobildern.
Den vollständigen Code und die zusätzlich verwendete Datei finden Sie unter dem Github-Link: https://github.com/cppxaxa/FaceRecognitionPipeline_GeeksForGeeks
Referenzen:
1. Adrians Blog-Beitrag zum Face-Clustering
2. PyPiper-Handbuch
3. OpenCV-Handbuch
4. StackOverflow
