Python | Lesen Sie csv mit pandas.read_csv()
Python ist eine großartige Sprache für die Datenanalyse, vor allem aufgrund des fantastischen Ökosystems datenzentrierter Python-Pakete. Pandas ist eines dieser Pakete und erleichtert das Importieren und Analysieren von Daten erheblich.
Pandas importieren:
Pandas als pd importieren
Code 1: read_csv ist eine wichtige Pandas-Funktion, um CSV-Dateien zu lesen und Operationen daran durchzuführen.
importpandas as pdpd.read_csv("filename.csv")
Das Öffnen einer CSV-Datei ist einfach. Es gibt aber noch viele andere Dinge, die man mit dieser Funktion tun kann, um das zurückgegebene Objekt vollständig zu ändern. Zum Beispiel kann man eine CSV-Datei nicht nur lokal lesen, sondern von einer URL über read_csv, oder man kann auswählen, welche Spalten exportiert werden sollen, damit wir das Array später nicht bearbeiten müssen.
Hier ist die Liste der Parameter, die mit ihren Standardwerten verwendet werden .
pd.read_csv (filepath_or_buffer, sep = ',', delimiter = None, header = 'infer', names = None, index_col = None, usecols = None, Squeeze = False, prefix = None, mangle_dupe_cols = True, dtype = None, engine = None, Konverter = Keine, true_values = Keine, false_values = Keine, skipinitialspace = False, skiprows = Keine, nrows = Keine, na_values = Keine, keep_default_na = True, na_filter = True, verbose = False, skip_blank_lines = True, parse_dates = False, infer_datetime_format = False, keep_date_col = False, date_parser = None, dayfirst = False, iterator = False, chunksize = None, Komprimierung = 'infer', Tausend = None, decimal = b '.', Lineterminator = None, quotechar = '' '', Anführungszeichen = 0, Escapeechar = Keine, Kommentar = Keine, Codierung = Keine, Dialekt = Keine, tupleize_cols = Keine, error_bad_lines = True, warn_bad_lines = True, skipfooter = 0, doublequote = True, delim_whitespace = False, low_memory = True, memory_map = False , float_precision = Keine)
Nicht alle von ihnen sind sehr wichtig, aber wenn Sie sich daran erinnern, sparen Sie tatsächlich Zeit, wenn Sie dieselben Funktionen alleine ausführen. Sie können Parameter jeder Funktion anzeigen, indem Sie im Jupyter-Notizbuch Umschalt + Tab drücken. Nützliche sind unten mit ihrer Verwendung angegeben:
| Parameter | Benutzen |
|---|---|
| Dateipfad_oder_Buffer | URL oder Dir Speicherort der Datei |
| sep | Steht für Trennzeichen, Standard ist ',' wie in csv (durch Kommas getrennte Werte) |
| index_col | Übergibt die Spalte als Index anstelle von 0, 1, 2, 3… r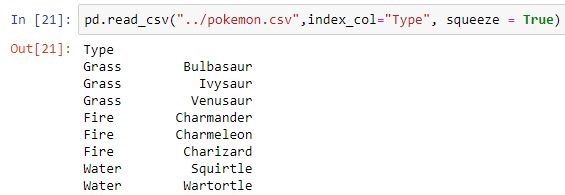
|
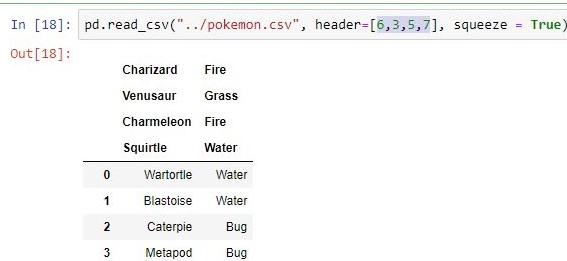
| Header | Übergibt die übergebenen Zeilen [int / int list] als Header
|
| use_cols | Verwendet nur die übergebene Spalte [Zeichenfolgenliste], um einen Datenrahmen zu erstellen |
| drücken | Wenn true und nur eine Spalte übergeben wird, werden Pandas-Serien zurückgegeben |
| Skiprows | Überspringt übergebene Zeilen in einem neuen Datenrahmen |
Siehe den Link zum Datensatz aus verwendet hier .
Code # 2:
importpandas as pdpd.read_csv(filepath_or_buffer="pokemon.csv")pd.read_csv("pokemon.csv", header=[1,2])pd.read_csv("pokemon.csv", index_col='Type')pd.read_csv("pokemon.csv", usecols=["Type"])pd.read_csv("pokemon.csv", usecols=["Type"],squeeze=True)pd.read_csv("pokemon.csv",skiprows=[1,2,3,4])