Python | Pandas Dataframe.rank()
Python ist eine großartige Sprache für die Datenanalyse, vor allem aufgrund des fantastischen Ökosystems datenzentrierter Python-Pakete. Pandas ist eines dieser Pakete und erleichtert das Importieren und Analysieren von Daten erheblich.
Die Pandas- Dataframe.rank()Methode gibt einen Rang für jeden Index einer übergebenen Serie zurück. Der Rang wird nach der Sortierung anhand der Position zurückgegeben.
Syntax:
DataFrame.rank (Achse = 0, Methode = 'Durchschnitt', numerisch_nur = Keine, na_option = 'behalten', aufsteigend = Wahr, pct = Falsch)
Parameters:
Achse: 0 oder 'Index' für Zeilen und 1 oder 'Spalten' für Spalte.
Methode: Nimmt eine Zeichenfolgeneingabe vor ('Durchschnitt', 'Min', 'Max', 'Erste', 'Dichte'), die Pandas mitteilt, was mit denselben Werten zu tun ist. Die Standardeinstellung ist Durchschnitt, was bedeutet, dass den ähnlichen Werten der Durchschnitt der Ränge zugewiesen wird.
numeric_only: Nimmt einen booleschen Wert an und die Rangfunktion funktioniert nur mit nicht numerischen Werten, wenn dieser falsch ist.
na_option: Es werden 3 Zeichenfolgen eingegeben ('keep', 'top', 'bottom'), um die Position der Nullwerte in der übergebenen Serie festzulegen .
aufsteigend: Boolescher Wert, der in aufsteigender Reihenfolge steht, wenn True.
pct: Boolescher Wert, der prozentual nach True eingestuft wird.
Return type:Serie mit Rang jedes Index der Anruferserien.
Klicken Sie hier, um einen Link zur im Code verwendeten CSV-Datei zu erhalten .
Beispiel 1: Rangfolge Spalte mit eindeutigen Werten
Im folgenden Beispiel wird eine neue Rangspalte erstellt, in der der Name jedes Spielers aufgeführt ist. Alle Werte in der Spalte Name sind eindeutig und daher muss keine Methode beschrieben werden.
importpandas as pddata=pd.read_csv("nba.csv")data["Rank"]=data["Name"].rank()datadata.sort_values("Name", inplace=True)data
Ausgabe:
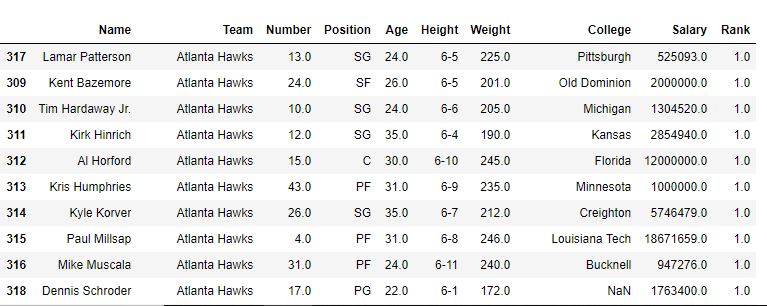
Wie im Bild gezeigt, wurde ein Spaltenrang mit dem Rang jedes Namens erstellt. Nachdem die Funktion sort_value den Datenrahmen in Bezug auf den Namen sortiert hat, ist ersichtlich, dass der Rang auch sortiert wurde, da es sich nur um eine Rangfolge von Namen handelte.
Vor dem Sortieren -
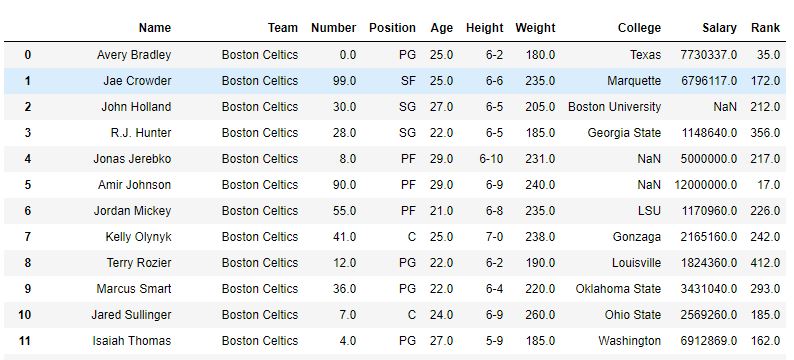
Nach dem Sortieren -
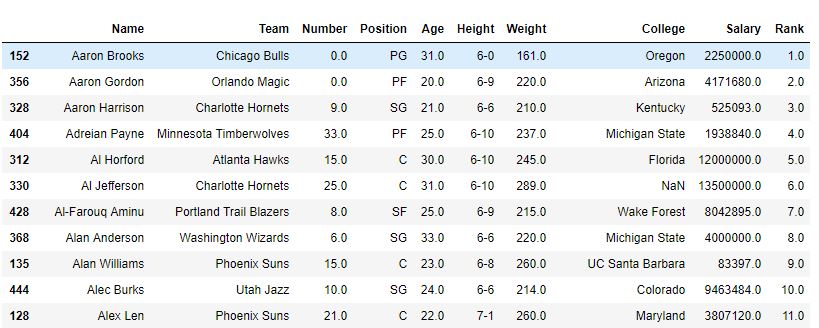
Beispiel 2: Sortieren der Spalte mit einigen ähnlichen Werten
Im folgenden Beispiel wird der Datenrahmen zuerst in Bezug auf den Teamnamen sortiert und zuerst wird die Methode als Standard (dh Durchschnitt) verwendet, und daher ist der Rang derselben Teamspieler durchschnittlich. Danach wird auch die min-Methode verwendet, um die Ausgabe anzuzeigen.
importpandas as pddata=pd.read_csv("nba.csv")data.sort_values("Team", inplace=True)data["Rank"]=data["Team"].rank(method='average')data
Ausgabe:
Mit Methode = 'Durchschnitt'
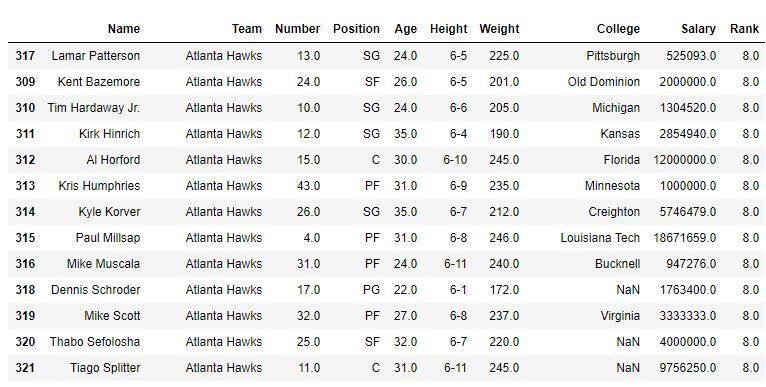
Mit Methode = 'min'