Selektive Suche nach Objekterkennung | R-CNN
Das Problem der Objektlokalisierung ist der schwierigste Teil der Objekterkennung. Ein Ansatz besteht darin, dass wir Schiebefenster unterschiedlicher Größe verwenden, um Objekte im Bild zu lokalisieren. Dieser Ansatz wird als erschöpfende Suche bezeichnet. Dieser Ansatz ist rechenintensiv, da wir selbst bei kleinen Bildgrößen in Tausenden von Fenstern nach Objekten suchen müssen. Es wurden einige Optimierungen vorgenommen, z. B. Fenstergrößen in unterschiedlichen Verhältnissen (anstatt sie um einige Pixel zu erhöhen). Aber auch danach ist es aufgrund der Anzahl der Fenster nicht sehr effizient. Dieser Artikel befasst sich mit dem selektiven Suchalgorithmus, der sowohl eine umfassende Suche als auch eine Segmentierung verwendet (eine Methode zum Trennen von Objekten mit unterschiedlichen Formen im Bild durch Zuweisen unterschiedlicher Farben).
Algorithmus der selektiven Suche:
- Generieren Sie eine anfängliche Untersegmentierung des Eingabebildes mit der Methode, die Felzenszwalb et al. In seiner Arbeit „Efficient Graph-Based Image Segmentation“ beschrieben haben.
- Kombinieren Sie rekursiv die kleineren ähnlichen Regionen zu größeren. Wir verwenden den Greedy-Algorithmus, um ähnliche Regionen zu größeren Regionen zu kombinieren. Der Algorithmus ist unten geschrieben.
Gieriger Algorithmus : 1. Wählen Sie aus einer Reihe von Regionen zwei Regionen aus, die am ähnlichsten sind. 2. Kombinieren Sie sie zu einer einzigen, größeren Region. 3. Wiederholen Sie die obigen Schritte für mehrere Iterationen.
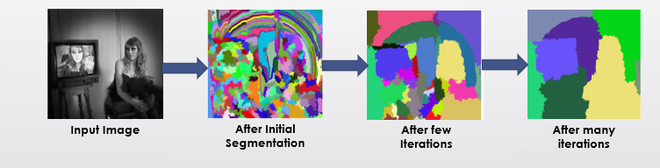
- Verwenden Sie die Vorschläge für segmentierte Regionen, um Kandidatenobjektpositionen zu generieren.
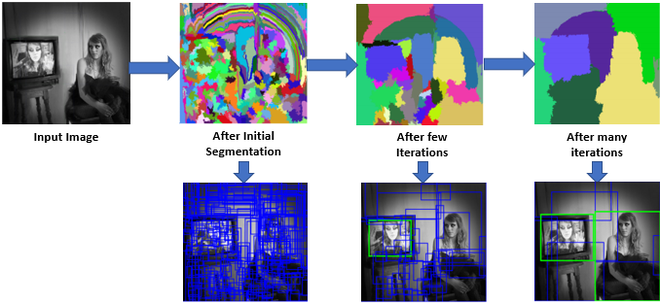

Ähnlichkeit in der Segmentierung:
Das selektive Suchpapier berücksichtigt vier Arten von Ähnlichkeit, wenn die anfängliche kleine Segmentierung in größere kombiniert wird. Diese Ähnlichkeiten sind:
- Farbähnlichkeit: Speziell für jede Region erstellen wir das Histogramm jedes im Bild vorhandenen Farbkanals. In diesem Artikel werden 25 Bins im Histogramm jedes Farbkanals aufgenommen. Dies ergibt 75 Bins (25 für jedes R, G und B) und alle Kanäle werden für jede Region zu einem Vektor (n = 75) kombiniert. Dann finden wir Ähnlichkeit unter Verwendung der folgenden Gleichung:
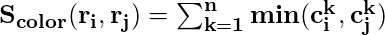
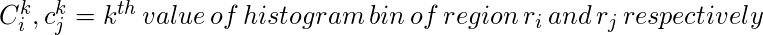
- Texturähnlichkeit: Die Texturähnlichkeit wird unter Verwendung von generierten 8 Gaußschen Ableitungen des Bildes berechnet und das Histogramm mit 10 Bins für jeden Farbkanal extrahiert. Dies ergibt 10 x 8 x 3 = 240 dimensionale Vektoren für jede Region. Wir leiten Ähnlichkeit unter Verwendung dieser Gleichung ab.
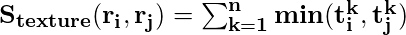
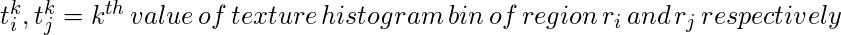
- Größenähnlichkeit: Die Grundidee der Größenähnlichkeit besteht darin, kleinere Regionen leicht zusammenführen zu lassen. Wenn diese Ähnlichkeit nicht berücksichtigt wird, werden nur an dieser Stelle größere Regionen mit Vorschlägen für größere Regionen und Regionen in mehreren Maßstäben zusammengeführt.
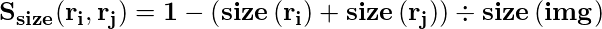
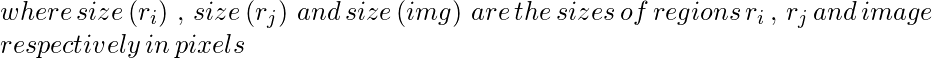
- Füllähnlichkeit: Die Füllähnlichkeit misst, wie gut zwei Regionen zueinander passen. Wenn zwei Regionen gut ineinander passen (zum Beispiel ist eine Region in einer anderen vorhanden), sollten sie zusammengeführt werden. Wenn sich zwei Regionen nicht einmal berühren, sollten sie nicht zusammengeführt werden.
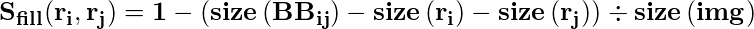
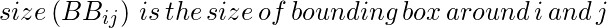
Nun, über vier Ähnlichkeiten kombiniert, um eine endgültige Ähnlichkeit zu bilden.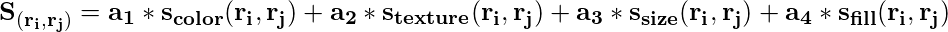

Ergebnisse :
Um die Leistung dieser Methode zu messen. Das Papier beschreibt einen Bewertungsparameter, der als MABO (Mean Average Best Overlap) bekannt ist.
Es gibt zwei Versionen der selektiven Suche kam schnell und Qualität . Der Unterschied zwischen ihnen besteht darin, dass Qualität viel mehr Begrenzungsrahmen erzeugt als Schnell und daher mehr Zeit für die Berechnung benötigt, jedoch einen höheren Rückruf und ABO (durchschnittliche beste Überlappung) und MABO (mittlere durchschnittliche beste Überlappung) aufweist. Wir haben ABO wie folgt berechnet.
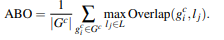
Wie wir beobachten können, gibt es uns das beste MABO, wenn alle Ähnlichkeiten in Kombination verwendet werden. Es kann jedoch auch der Schluss gezogen werden, dass RGB nicht das beste Farbschema für dieses Verfahren ist. HSV, Lab und rgI bieten eine bessere Leistung als RGB. Dies liegt daran, dass diese nicht empfindlich auf Schatten und Helligkeitsänderungen reagieren.
Wenn wir diese unterschiedlichen Ähnlichkeiten, Farbschemata und Schwellenwerte (k) diversifizieren und kombinieren,
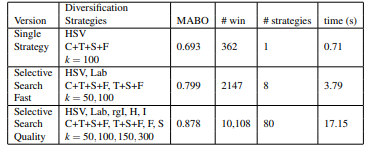
In einem selektiven Suchpapier wird eine auf MABO basierende gierige Methode auf verschiedene Strategien angewendet, um über die Ergebnisse zu gelangen. Wir können sagen, dass diese Methode der Kombination verschiedener Strategien zwar eine bessere MABO ergibt, aber auch die Laufzeit erheblich zunimmt.
Selektive Suche in der Objekterkennung:
In einem selektiven Suchpapier verwenden die Autoren diesen Algorithmus zur Objekterkennung und trainieren ein Modell, indem sie Beispiele für die Grundwahrheit und eine Stichprobenhypothese angeben, die sich zu 20-50% mit der Grundwahrheit (als negatives Beispiel) überlappen, und trainieren sie, um falsch positive zu identifizieren. Die Architektur des verwendeten Modells wird unten angegeben.

Objekterkennungsarchitektur (Quelle: Selective Search Paper)
Das mit dem VOC 2007-Testsatz generierte Ergebnis lautet:
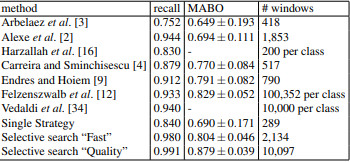
Wie wir sehen können, erzeugt es einen sehr hohen Rückruf und das beste MABO auf dem VOC 2007-Testsatz und es erfordert viel weniger zu verarbeitende Fenster als andere Algorithmen, die einen ähnlichen Rückruf und MABO erzielen.
Anwendungen:
Die selektive Suche wird häufig in modernen Architekturen wie R-CNN, Fast R-CNN usw. verwendet. Aufgrund der Anzahl der verarbeiteten Fenster dauert sie jedoch zwischen 1,8 und 3,7 Sekunden (Selective Search Fast). einen Regionsvorschlag zu generieren, der für ein Echtzeit-Objekterkennungssystem nicht gut genug ist.
Referenz :
