Spracherkennung in Python mithilfe der Google Speech API
Die Spracherkennung ist eine wichtige Funktion in verschiedenen Anwendungen, wie z. B. Hausautomation, künstliche Intelligenz usw. Dieser Artikel enthält eine Einführung in die Verwendung der SpeechRecognition-Bibliothek von Python. Dies ist nützlich, da es mit Hilfe eines externen Mikrofons auf Mikrocontrollern wie Raspberri Pis verwendet werden kann.
Erforderliche Installationen
Folgendes muss installiert sein:
- Python-Spracherkennungsmodul:
sudo pip install SpeechRecognition
- PyAudio: Verwenden Sie den folgenden Befehl für Linux-Benutzer
sudo apt-get install python-pyaudio python3-pyaudio
Wenn die Versionen in den Repositorys zu alt sind, installieren Sie pyaudio mit dem folgenden Befehl
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev && sudo pip install pyaudio
Verwenden Sie pip3 anstelle von pip für python3.
Windows-Benutzer können pyaudio installieren, indem sie den folgenden Befehl in einem Terminal ausführen
pip install pyaudio
Spracheingabe mit einem Mikrofon und Übersetzung von Sprache in Text
-
Mikrofon konfigurieren (für externe Mikrofone): Es wird empfohlen, das Mikrofon während des Programms anzugeben, um Störungen zu vermeiden.
Geben Sie lsusb im Terminal. Eine Liste der angeschlossenen Geräte wird angezeigt. Der Mikrofonname würde so aussehenUSB-Gerät 0x46d: 0x825: Audio (hw: 1, 0)
Notieren Sie sich dies, da es im Programm verwendet wird.
- Festlegen der Blockgröße: Hierbei wurde im Wesentlichen angegeben, wie viele Datenbytes gleichzeitig gelesen werden sollen. Normalerweise wird dieser Wert in Potenzen von 2 angegeben, z. B. 1024 oder 2048
- Abtastrate einstellen: Die Abtastrate definiert, wie oft Werte zur Verarbeitung aufgezeichnet werden
- Geräte-ID auf das ausgewählte Mikrofon einstellen : In diesem Schritt geben wir die Geräte-ID des Mikrofons an, das wir verwenden möchten, um Mehrdeutigkeiten bei mehreren Mikrofonen zu vermeiden. Dies hilft auch beim Debuggen in dem Sinne, dass wir beim Ausführen des Programms wissen, ob das angegebene Mikrofon erkannt wird. Während des Programms geben wir einen Parameter device_id an. Das Programm sagt, dass device_id nicht gefunden werden konnte, wenn das Mikrofon nicht erkannt wird.
- Anpassung für Umgebungsgeräusche zulassen: Da das Umgebungsgeräusch variiert, müssen wir dem Programm eine Sekunde oder auch Zeit geben, um die Energieschwelle der Aufzeichnung so anzupassen, dass sie entsprechend dem externen Geräuschpegel angepasst wird.
- Übersetzung von Sprache in Text: Dies erfolgt mithilfe der Google-Spracherkennung. Dies erfordert eine aktive Internetverbindung, um zu funktionieren. Es gibt jedoch bestimmte Offline-Erkennungssysteme wie PocketSphinx, die jedoch einen sehr strengen Installationsprozess aufweisen, der mehrere Abhängigkeiten erfordert. Die Google-Spracherkennung ist eine der am einfachsten zu verwendenden.
Die obigen Schritte wurden unten implementiert:
bearbeiten
schließen
play_arrow
Link
Helligkeit_4
Code
import speech_recognition as sr mic_name = "USB Device 0x46d:0x825: Audio (hw:1, 0)"sample_rate = 48000chunk_size = 2048r = sr.Recognizer() mic_list = sr.Microphone.list_microphone_names() for i, microphone_name in enumerate(mic_list): if microphone_name == mic_name: device_id = i with sr.Microphone(device_index = device_id, sample_rate = sample_rate, chunk_size = chunk_size) as source: r.adjust_for_ambient_noise(source) print "Say Something"audio = r.listen(source) try: text = r.recognize_google(audio) print "you said: " + text except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e)) |
Übertragen Sie eine Audiodatei in Text
Wenn wir eine Audiodatei haben, die wir in Text übersetzen möchten, müssen wir einfach die Quelle durch die Audiodatei anstelle eines Mikrofons ersetzen.
Legen Sie die Audiodatei und das Programm zur Vereinfachung im selben Ordner ab. Dies funktioniert für WAV, AIFF und FLAC-Dateien.
Eine Implementierung wurde unten gezeigt
bearbeiten
schließen
play_arrow
Link
Helligkeit_4
Code
import speech_recognition as sr AUDIO_FILE = ("example.wav") r = sr.Recognizer() with sr.AudioFile(AUDIO_FILE) as source: audio = r.record(source) try: print("The audio file contains: " + r.recognize_google(audio)) except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e)) |
Fehlerbehebung
Die folgenden Probleme treten häufig auf
- Stummgeschaltetes Mikrofon: Dies führt dazu, dass keine Eingaben empfangen werden. Um dies zu überprüfen, können Sie alsamixer verwenden.
Es kann mit installiert werden
sudo apt-get install libasound2 alsa-utils alsa-oss
Typ amixer . Die Ausgabe sieht ungefähr so aus
Einfache Mischersteuerung 'Master', 0 Funktionen: pvolume pswitch pswitch-join Wiedergabekanäle: Vorne links - Vorne rechts Limits: Wiedergabe 0 - 65536 Mono: Vorne links: Wiedergabe 41855 [64%] [Ein] Vorne rechts: Wiedergabe 65536 [100%] [Ein] Einfache Mischersteuerung 'Capture', 0 Funktionen: cvolume cswitch cswitch-join Kanäle erfassen: Vorne links - Vorne rechts Grenzen: Erfassen Sie 0 - 65536 Vorne links: Aufnahme 0 [0%] [aus] # ausgeschaltet Vorne rechts: Erfassen Sie 0 [0%] [aus]
Wie Sie sehen können, ist das Aufnahmegerät derzeit ausgeschaltet. Um es einzuschalten, geben
Sie alsamixer ein. Wie Sie im ersten Bild sehen können, werden unsere Wiedergabegeräte angezeigt . Drücken Sie F4, um zwischen Geräte erfassen umzuschalten.
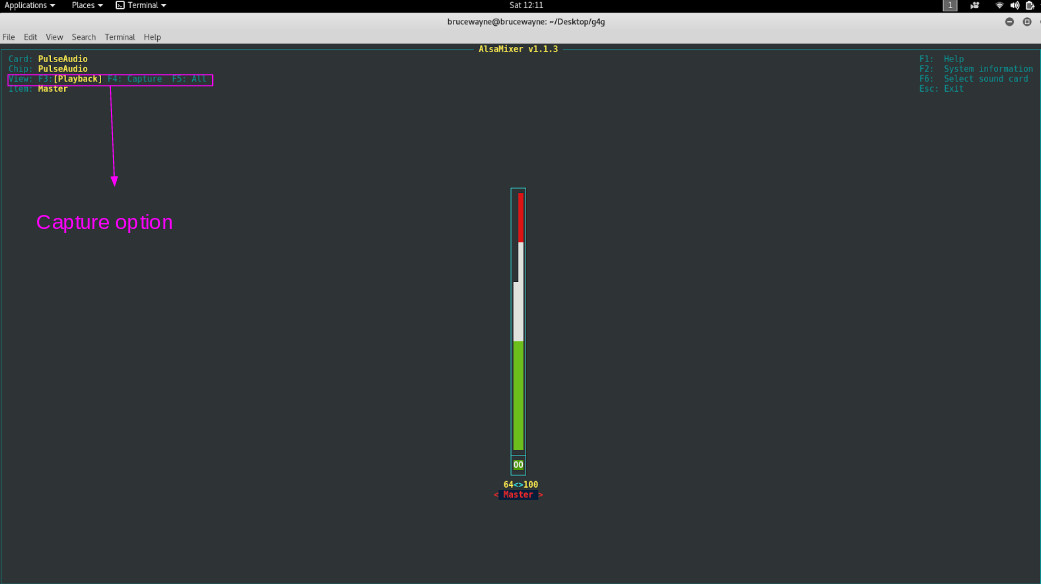
Im zweiten Bild zeigt der hervorgehobene Teil, dass das Aufnahmegerät stummgeschaltet ist. Drücken Sie die Leertaste, um die Stummschaltung aufzuheben

Wie Sie im letzten Bild sehen können, bestätigt der hervorgehobene Teil, dass das Aufnahmegerät nicht stummgeschaltet ist.

- Aktuelles Mikrofon nicht als Aufnahmegerät ausgewählt:
In diesem Fall kann das Mikrofon durch Eingabe von alsamixer und Auswahl von Soundkarten eingestellt werden. Hier können Sie das Standardmikrofon auswählen.
Wie in der Abbildung gezeigt, müssen Sie im hervorgehobenen Bereich die Soundkarte auswählen.

Das zweite Bild zeigt die Bildschirmauswahl für die Soundkarte

- Keine Internetverbindung: Für die Konvertierung von Sprache in Text ist eine aktive Internetverbindung erforderlich.
Dieser Artikel wurde von Deepak Srivatsav verfasst . Wenn Ihnen GeeksforGeeks gefällt und Sie einen Beitrag leisten möchten, können Sie auch einen Artikel mit Contrib.geeksforgeeks.org schreiben oder Ihren Artikel an Contribute@geeksforgeeks.org senden . Sehen Sie sich Ihren Artikel auf der GeeksforGeeks-Hauptseite an und helfen Sie anderen Geeks.
Bitte schreiben Sie Kommentare, wenn Sie etwas Falsches finden oder weitere Informationen zu dem oben diskutierten Thema teilen möchten.
