Verwenden des CSV-Moduls zum Lesen der Daten in Pandas
Das sogenannte CSV-Format (Comma Separated Values) ist das am häufigsten verwendete Import- und Exportformat für Tabellenkalkulationen und Datenbanken. Bis zu seiner Standardisierung gab es verschiedene CSV-Formate. Das Fehlen eines genau definierten Standards führt dazu, dass häufig subtile Unterschiede in den Daten bestehen, die von verschiedenen Anwendungen erzeugt und verbraucht werden. Diese Unterschiede können es ärgerlich machen, CSV-Dateien aus mehreren Quellen zu verarbeiten. Zu diesem Zweck verwenden wir die Python- csvBibliothek zum Lesen und Schreiben von Tabellendaten im CSV-Format.
Klicken Sie hier, um einen Link zur im Code verwendeten CSV-Datei zu erhalten .
Code 1: Wir werden die csv.DictReader()Funktion verwenden, um die Datendatei in die Umgebung von Python zu importieren.
importcsvwithopen('auto-mpg.csv') as csvfile:mpg_data=list(csv.DictReader(csvfile))(mpg_data[:3])
Ausgabe:
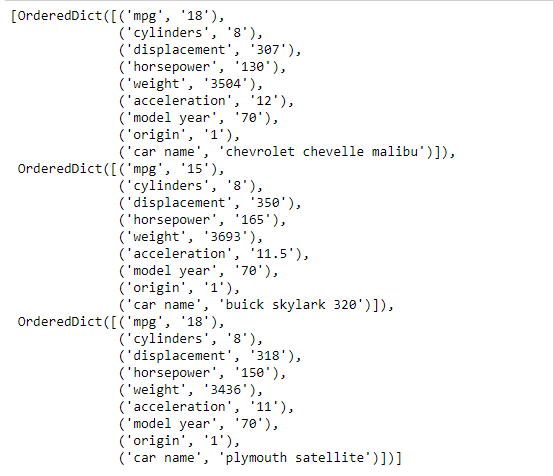
Wie wir sehen können, werden die Daten als Liste des geordneten Wörterbuchs gespeichert. Lassen Sie uns zum besseren Verständnis einige Operationen an den Daten ausführen.
Code # 2:
(mpg_data[0].keys)unique_cyl=set(data['cylinders']fordatainmpg_data)(unique_cyl)
Ausgabe:
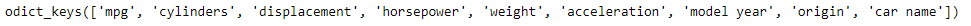
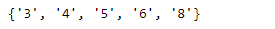
Wie wir in der Ausgabe sehen können, haben wir 5 eindeutige Zylinderwerte in unserem Datensatz.
Code 3: Lassen Sie uns nun den Wert der durchschnittlichen mpg für jeden Wert der Zylinder herausfinden.
avg_mpg=[]forcinunique_cyl:mpgbycyl=0cylcount=0forxinmpg_data:ifx['cylinders']==c:mpgbycyl+=float(x['mpg'])cylcount+=1avg=mpgbycyl/cylcountavg_mpg.append((c, avg))avg_mpg.sort(key=lambdax : x[0])(avg_mpg)
Ausgabe :
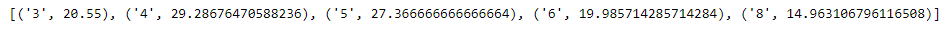
Wie wir in der Ausgabe sehen können, hat das Programm erfolgreich eine Liste von Tupeln zurückgegeben, die die durchschnittliche mpg für jeden einzelnen Zylindertyp in unserem Datensatz enthalten.