Vorhersage des Luftqualitätsindex mit Python
Lassen Sie uns sehen, wie der Luftqualitätsindex mit Python vorhergesagt werden kann. Der AQI wird basierend auf der Menge der chemischen Schadstoffe berechnet. Durch machine learning können wir den AQI vorhersagen.
AQI: Der Luftqualitätsindex ist ein Index für die tägliche Berichterstattung über die Luftqualität. Mit anderen Worten, es ist ein Maß dafür, wie sich die Luftverschmutzung innerhalb kurzer Zeit auf die Gesundheit auswirkt. Der AQI wird basierend auf der durchschnittlichen Konzentration eines bestimmten Schadstoffs berechnet, die über ein Standardzeitintervall gemessen wurde. Im Allgemeinen beträgt das Zeitintervall für die meisten Schadstoffe 24 Stunden, für Kohlenmonoxid und Ozon 8 Stunden.
Wir können anhand des AQI sehen, wie hoch die Luftverschmutzung ist
| AQI Level | AQI-Bereich |
| Gut | 0 - 50 |
| Mäßig | 51 - 100 |
| Ungesund | 101 - 150 |
| Ungesund für starke Leute | 151 - 200 |
| Gefährlich | 201+ |
Lassen Sie uns den AQI basierend auf chemischen Schadstoffen mithilfe des Machine Learning-Konzepts ermitteln.
Hinweis: Um den Datensatz herunterzuladen, klicken Sie hier .
Datensatzbeschreibung
Es enthält 8 Attribute, von denen 7 chemische Verschmutzungsmengen und eines der Luftqualitätsindex sind. PM2.5-AVG, PM10-AVG, NO2-AVG, NH3-AVG, SO2-AG und OZONE-AVG sind unabhängige Attribute. air_quality_index ist ein abhängiges Attribut. Da air_quality_index basierend auf den 7 Attributen berechnet wird.
Da die Daten numerisch sind und keine fehlenden Werte in den Daten vorhanden sind, ist keine Vorverarbeitung erforderlich. Unser Ziel ist es, den AQI vorherzusagen. Diese Aufgabe ist also entweder Klassifizierung oder Regression. Da unser Klassenlabel kontinuierlich ist, ist eine Regressionstechnik erforderlich.
Regression ist eine überwachte Lerntechnik, die zu den Daten in einem bestimmten Bereich passt. Beispiel für Regressionstechniken in Python:
- Zufälliger Waldregressor
- Ada Boost Regressor
- Bagging Regressor
- Lineare Regression usw.
importpandas as pdtrain=pd.read_csv('AQI.csv')train.head()
Ausgabe:
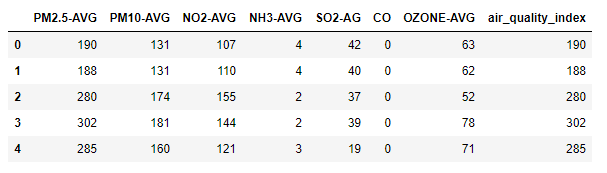
fromsklearn.ensembleimportAdaBoostRegressorfromsklearn.ensembleimportRandomForestRegressorm1=RandomForestRegressor()train1=train.drop(['air_quality_index'], axis=1)target=train['air_quality_index']m1.fit(train1, target)m1.score(train1, target)*100m1.predict([[123,45,67,34,5,0,23]])m2=AdaBoostRegressor()m2.fit(train1, target)m2.score(train1, target)*100m2.predict([[123,45,67,34,5,0,23]])
Ausgabe:
Auf diese Weise können wir sagen, dass wir durch gegebene Testdaten 123 und 95 erhalten haben, so dass der AQI ungesund ist.
