Wie erstelle ich eine Pivot-Tabelle in Python mit Pandas?
Die Pivot-Tabelle ist eine statistische Tabelle, die eine umfangreiche Tabelle wie große Datenmengen zusammenfasst. Es ist Teil der Datenverarbeitung. Diese Zusammenfassung in Pivot-Tabellen kann Mittelwert, Median, Summe oder andere statistische Begriffe enthalten. Pivot-Tabellen sind ursprünglich mit MS Excel verknüpft, aber wir können eine Pivot-Tabelle in Python mithilfe von Pandas mithilfe der Methode dataframe.pivot() erstellen .
Syntax: dataframe.pivot (self, index = Keine, Spalten = Keine, Werte = Keine, aggfunc)
Parameter -
Index: Spalte zum Erstellen des Index eines neuen Frames.
Spalten: Spalte für die Spalten des neuen Frames.
Werte: Spalte (n) zum Auffüllen der Werte neuer Frames.
aggfunc: Funktion, Liste der Funktionen, Diktat, Standard numpy.mean
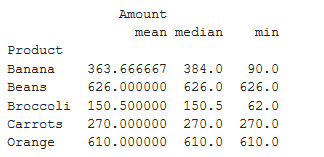
Beispiel 1:
Erstellen wir zunächst einen Datenrahmen, der den Verkauf von Früchten enthält.
importpandas as pddf=pd.DataFrame({'Product': ['Carrots','Broccoli','Banana','Banana','Beans','Orange','Broccoli','Banana'],'Category': ['Vegetable','Vegetable','Fruit','Fruit','Vegetable','Fruit','Vegetable','Fruit'],'Quantity': [8,5,3,4,5,9,11,8],'Amount': [270,239,617,384,626,610,62,90]})df
Ausgabe: