Wie erstelle ich mit Pandas mehrere CSV-Dateien aus einer vorhandenen CSV-Datei?
In diesem Artikel erfahren Sie, wie Sie mit Pandas mehrere CSV-Dateien aus einer vorhandenen CSV-Datei erstellen. Wenn wir unseren Code in die Produktion eingeben, müssen wir uns mit der Bearbeitung unserer Datendateien befassen. Aufgrund der großen Größe der Datendatei werden wir auf mehr Probleme stoßen, also haben wir diese Datei in einige kleine Dateien aufgeteilt, basierend auf einigen Kriterien wie Aufteilung in Zeilen, Spalten, bestimmte Spaltenwerte usw.
Lassen Sie uns zunächst eine einfache CSV-Datei erstellen und diese für alle Beispiele weiter unten im Artikel verwenden. Erstellen Sie einen Datensatz mit der Datenrahmenmethode von Pandas und speichern Sie ihn dann in der Datei „Customers.csv“, oder wir können einen vorhandenen Datensatz mit der Pandas-Funktion read_csv() laden.
Python3
import pandas as pd
# initialise data dictionary.
data_dict = {'CustomerID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'Gender': ["Male", "Female", "Female", "Male",
"Male", "Female", "Male", "Male",
"Female", "Male"],
'Age': [20, 21, 19, 18, 25, 26, 32, 41, 20, 19],
'Annual Income(k$)': [10, 20, 30, 10, 25, 60, 70,
15, 21, 22],
'Spending Score': [30, 50, 48, 84, 90, 65, 32, 46,
12, 56]}
# Create DataFrame
data = pd.DataFrame(data_dict)
# Write to CSV file
data.to_csv("Customers.csv")
# Print the output.
print(data)
Ausgabe:
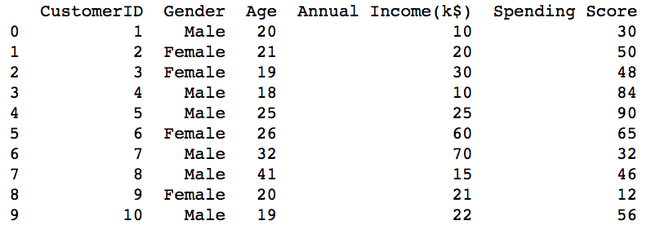
Erstellen mehrerer CSV-Dateien aus der vorhandenen CSV-Datei
Um unsere Arbeit zu erledigen, werden wir verschiedene Methoden besprechen, die wie folgt sind:
Methode 1: Aufteilen basierend auf Zeilen
Bei dieser Methode teilen wir eine CSV-Datei basierend auf Zeilen in mehrere CSVs auf.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
# no of csv files with row size
k = 2
size = 5
for i in range(k):
df = data[size*i:size*(i+1)]
df.to_csv(f'Customers_{i+1}.csv', index=False)
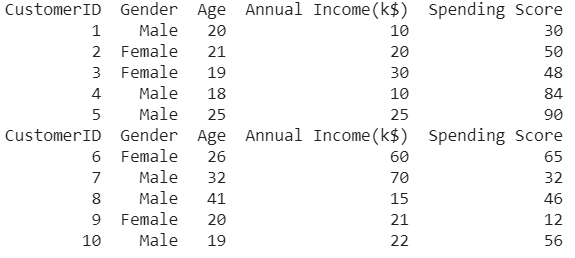
df_1 = pd.read_csv("Customers_1.csv")
print(df_1)
df_2 = pd.read_csv("Customers_2.csv")
print(df_2)
Ausgabe:
Methode 2: Aufteilen basierend auf Spalten
Beispiel 1:
Mit der Methode groupby() von Pandas können wir mehrere CSV-Dateien erstellen. Um eine Datei zu erstellen, können wir die Methode to_csv() von Pandas verwenden. Hier wurden zwei Dateien erstellt, die auf den Werten „männlich“ und „weiblich“ der Geschlechtsspalten basieren.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
for (gender), group in data.groupby(['Gender']):
group.to_csv(f'{gender}.csv', index=False)
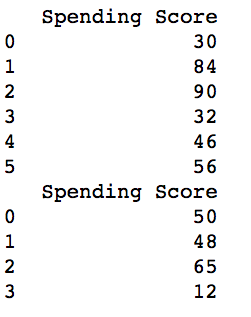
print(pd.read_csv("Male.csv"))
print(pd.read_csv("Female.csv"))
Ausgabe:
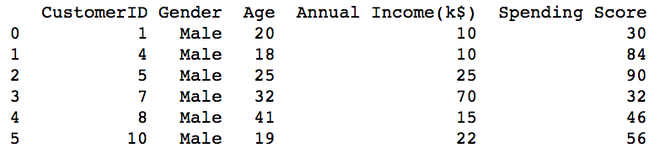
Männlich.csv
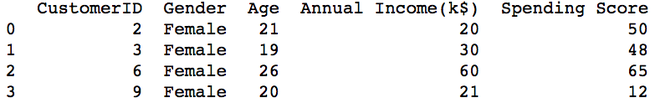
Weiblich.csv
Beispiel 2:
Wir können mehr als zwei Spalten gruppieren und mehrere Dateien auf der Grundlage einer Kombination eindeutiger Werte aus beiden Spaltenwerten erstellen. Nehmen Sie die Spalten Geschlecht und Jahreseinkommen.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
for (Gender, Income), group in data.groupby(['Gender', 'Annual Income(k$)']):
group.to_csv(f'{Gender} {Income}.csv', index=False)
print(pd.read_csv(f'{Gender} {Income}.csv'))
Ausgabe:
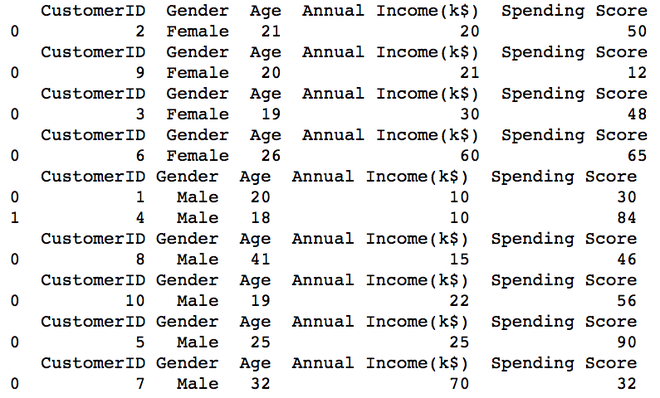
Alle neun CSV-Dateien
Beispiel 3:
Wir filtern die Spalten basierend auf dem spezifischen Spaltennamen Geschlecht nach seinen Werten (männlich und weiblich). Konvertieren Sie diese dann mit to_csv in Pandas in eine CSV-Datei.
Python3
import pandas as pd
# read DataFrame
data = pd.read_csv("Customers.csv")
male = data[data['Gender'] == 'Male']
female = data[data['Gender'] == 'Female']
male.to_csv('Gender_male.csv', index=False)
female.to_csv('Gender_female.csv', index=False)
print(pd.read_csv("Gender_male.csv"))
print(pd.read_csv("Gender_female.csv"))
Ausgabe:
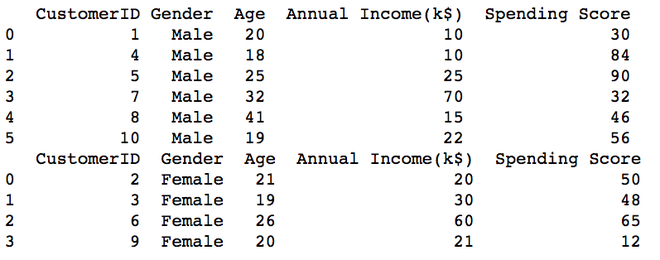
Methode 3: Aufteilen basierend sowohl auf Zeilen als auch auf Spalten
Mit der Methode groupby() von Pandas können wir mehrere CSV-Dateien zeilenweise erstellen. Um eine Datei zu erstellen, können wir die Methode to_csv() von Pandas verwenden. Hier wurden zwei Dateien erstellt, die auf den Zeilenwerten „männlich“ und „weiblich“ der spezifischen Spalte „Geschlecht“ für den Ausgaben-Score basieren.
Python3
for (gender), group in data['Spending Score'].groupby(data['Gender']):
group.to_csv(f'{gender}Score.csv', index=False)
print(pd.read_csv("MaleScore.csv"))
print(pd.read_csv("FemaleScore.csv"))
Ausgabe: