Arbeiten mit CSV-Dateien in Python
In diesem Artikel wird erläutert, wie Sie eine CSV-Datei in Python laden und analysieren.
Was ist eine CSV?
CSV (Comma Separated Values) ist ein einfaches Dateiformat verwendet tabellarische Daten zu speichern, wie eine Tabellenkalkulation oder Datenbank. In einer CSV-Datei werden Tabellendaten (Zahlen und Text) im Klartext gespeichert. Jede Zeile der Datei ist ein Datensatz. Jeder Datensatz besteht aus einem oder mehreren Feldern, die durch Kommas getrennt sind. Die Verwendung des Kommas als Feldtrennzeichen ist die Quelle des Namens für dieses Dateiformat.
Für die Arbeit mit CSV-Dateien in Python gibt es ein eingebautes Modul namens csv .
Lesen einer CSV-Datei
importcsvfilename="aapl.csv"fields=[]rows=[]withopen(filename,'r') as csvfile:csvreader=csv.reader(csvfile)fields=next(csvreader)forrowincsvreader:rows.append(row)("Total no. of rows: %d"%(csvreader.line_num))('Field names are:'+', '.join(fieldforfieldinfields))('\nFirst 5 rows are:\n')forrowinrows[:5]:forcolinrow:("%10s"%col),('\n')
Die Ausgabe des obigen Programms sieht folgendermaßen aus:
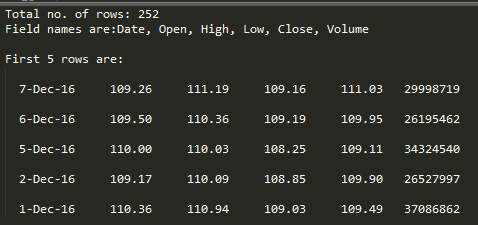
Im obigen Beispiel wird eine CSV-Datei aapl.csv verwendet, die hier heruntergeladen werden kann .
Führen Sie dieses Programm mit der Datei aapl.csv im selben Verzeichnis aus.
Versuchen wir, diesen Code zu verstehen.
-
mit open (Dateiname, 'r') als csvfile: csvreader = csv.reader (csvfile)Hier öffnen wir zuerst die CSV-Datei im READ-Modus. Das Dateiobjekt heißt csvfile . Das Dateiobjekt wird in das Objekt csv.reader konvertiert. Wir speichern das Objekt csv.reader als csvreader .
-
fields = csvreader.next()
csvreader ist ein iterierbares Objekt. Daher gibt die Methode .next() die aktuelle Zeile zurück und bringt den Iterator in die nächste Zeile. Da die erste Zeile unserer CSV-Datei die Header (oder Feldnamen) enthält, speichern wir sie in einer Liste namens Felder .
-
für Zeile in csvreader: rows.append (row)Jetzt durchlaufen wir die verbleibenden Zeilen mit einer for-Schleife. Jede Zeile wird an eine Liste mit dem Namen Zeilen angehängt . Wenn Sie versuchen, jede Zeile zu drucken, können Sie feststellen, dass diese Zeile nichts anderes als eine Liste ist, die alle Feldwerte enthält.
-
print ("Gesamtzahl der Zeilen:% d"% (csvreader.line_num))csvreader.line_num ist nichts anderes als ein Zähler, der die Anzahl der iterierten Zeilen zurückgibt.
Schreiben in eine CSV-Datei
importcsvfields=['Name','Branch','Year','CGPA']rows=[ ['Nikhil','COE','2','9.0'],['Sanchit','COE','2','9.1'],['Aditya','IT','2','9.3'],['Sagar','SE','1','9.5'],['Prateek','MCE','3','7.8'],['Sahil','EP','2','9.1']]filename="university_records.csv"withopen(filename,'w') as csvfile:csvwriter=csv.writer(csvfile)csvwriter.writerow(fields)csvwriter.writerows(rows)
Versuchen wir, den obigen Code in Teilen zu verstehen.
- Felder und Zeilen wurden bereits definiert. Felder ist eine Liste, die alle Feldnamen enthält. Zeilen ist eine Liste von Listen. Jede Zeile ist eine Liste mit den Feldwerten dieser Zeile.
-
mit open (Dateiname, 'w') als csvfile: csvwriter = csv.writer (csvfile)Hier öffnen wir zuerst die CSV-Datei im WRITE-Modus. Das Dateiobjekt heißt csvfile . Das Dateiobjekt wird in das Objekt csv.writer konvertiert. Wir speichern das Objekt csv.writer als csvwriter .
-
csvwriter.writerow (Felder)
Jetzt verwenden wir die writerow- Methode, um die erste Zeile zu schreiben, die nichts anderes als die Feldnamen ist.
-
csvwriter.writerows (Zeilen)
Wir verwenden die Writerows- Methode, um mehrere Zeilen gleichzeitig zu schreiben.
Schreiben eines Wörterbuchs in eine CSV-Datei
importcsvmydict=[{'branch':'COE','cgpa':'9.0','name':'Nikhil','year':'2'},{'branch':'COE','cgpa':'9.1','name':'Sanchit','year':'2'},{'branch':'IT','cgpa':'9.3','name':'Aditya','year':'2'},{'branch':'SE','cgpa':'9.5','name':'Sagar','year':'1'},{'branch':'MCE','cgpa':'7.8','name':'Prateek','year':'3'},{'branch':'EP','cgpa':'9.1','name':'Sahil','year':'2'}]fields=['name','branch','year','cgpa']filename="university_records.csv"withopen(filename,'w') as csvfile:writer=csv.DictWriter(csvfile, fieldnames=fields)writer.writeheader()writer.writerows(mydict)
In diesem Beispiel schreiben wir ein Wörterbuch mydict in eine CSV-Datei.
-
mit open (Dateiname, 'w') als csvfile: writer = csv.DictWriter (csvfile, fieldnames = fields)Hier wird das Dateiobjekt ( csvfile ) in ein DictWriter-Objekt konvertiert.
Hier geben wir die Feldnamen als Argument an. -
writer.writeheader()
Die Methode writeheader schreibt einfach die erste Zeile Ihrer CSV-Datei unter Verwendung der vorgegebenen Feldnamen.
-
writer.writerows (mydict)
Die writerows- Methode schreibt einfach alle Zeilen, aber in jede Zeile werden nur die Werte (keine Schlüssel) geschrieben.
Am Ende sieht unsere CSV-Datei also so aus:
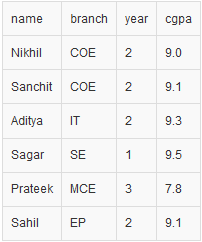
Wichtige Punkte:
- In CSV-Modulen kann ein optionaler Dialektparameter angegeben werden, mit dem eine Reihe von Parametern definiert wird, die für ein bestimmtes CSV-Format spezifisch sind . Standardmäßig verwendet das CSV-Modul Excel- Dialekt, wodurch es mit Excel-Tabellen kompatibel ist. Sie können Ihren eigenen Dialekt mit der Methode register_dialect definieren .
Hier ist ein Beispiel:
csv.register_dialect(
'mydialect',
delimiter = ',',
quotechar = '"',
doublequote = True,
skipinitialspace = True,
lineterminator = '\r\n',
quoting = csv.QUOTE_MINIMAL)Während wir nun ein csv.reader- oder csv.writer-Objekt definieren, können wir den Dialekt wie folgt angeben
:
csvreader = csv.reader(csvfile, dialect='mydialect')- Bedenken Sie nun, dass eine CSV-Datei im Klartext so aussieht:
 Wir stellen fest, dass das Trennzeichen kein Komma, sondern ein Semikolon ist. Außerdem werden die Zeilen durch zwei Zeilenumbrüche anstelle von einer getrennt. In solchen Fällen können wir das Trennzeichen und den Zeilenabschluss wie folgt angeben:
Wir stellen fest, dass das Trennzeichen kein Komma, sondern ein Semikolon ist. Außerdem werden die Zeilen durch zwei Zeilenumbrüche anstelle von einer getrennt. In solchen Fällen können wir das Trennzeichen und den Zeilenabschluss wie folgt angeben:
csvreader = csv.reader(csvfile, delimiter = ';', lineterminator = '\n\n')
Dies war also eine kurze, aber präzise Diskussion darüber, wie CSV-Dateien in ein Python-Programm geladen und analysiert werden.
Dieser Blog wurde von Nikhil Kumar verfasst . Wenn Ihnen GeeksforGeeks gefällt und Sie einen Beitrag leisten möchten, können Sie auch einen Artikel mit Contrib.geeksforgeeks.org schreiben oder Ihren Artikel an Contribute@geeksforgeeks.org senden. Sehen Sie sich Ihren Artikel auf der GeeksforGeeks-Hauptseite an und helfen Sie anderen Geeks.
Bitte schreiben Sie Kommentare, wenn Sie etwas Falsches finden oder weitere Informationen zu dem oben diskutierten Thema teilen möchten.
