Erstellen von Dateien in HDFS mit Python Snakebite
Hadoop ist ein beliebtes Big-Data-Framework, das in Java geschrieben wurde. Es ist jedoch nicht erforderlich, Java für die Arbeit an Hadoop zu verwenden. Einige andere Programmiersprachen wie Python , C ++ können ebenfalls verwendet werden. Wir können C ++ - Code für Hadoop mithilfe der Pipes-API oder der Hadoop-Pipes schreiben. Hadoop-Pipes ermöglichen den Task-Tracker mithilfe von Sockets.
Python kann auch zum Schreiben von Code für Hadoop verwendet werden. Snakebite ist eine der beliebtesten Bibliotheken, mit denen die Kommunikation mit dem HDFS hergestellt wird . Mit der vom Snakebite-Paket bereitgestellten Python-Client-Bibliothek können wir problemlos Python-Code schreiben, der unter HDFS funktioniert. Es verwendet Protobuf- Nachrichten, um direkt mit dem NameNode zu kommunizieren. Die Python-Client-Bibliothek funktioniert direkt mit HDFS, ohne dass ein Systemaufruf an hdfs dfs erfolgt .
Voraussetzung: Die Snakebite-Bibliothek sollte installiert sein.
Stellen Sie sicher, dass Hadoop ausgeführt wird. Wenn nicht, starten Sie alle Dämonen mit dem folgenden Befehl.
start-dfs.sh // starte deinen Namensknoten-Datenknoten und den sekundären Namensknoten start-yarn.sh // resourcemanager und nodemanager starten
Aufgabe: Erstellen Sie Verzeichnisse in HDFS mithilfe des Snakebite-Pakets mit der Methode mkdir() .
Schritt 1: Erstellen Sie eine Datei in Ihrem lokalen Verzeichnis mit dem Namen create_directory.py am gewünschten Speicherort .
cd Dokumente / # Verzeichnis in Dokumente ändern (Sie können nach Ihren Wünschen auswählen) Der Befehl touch create_directory.py # touch wird verwendet, um eine Datei in Linux-Umgebung zu erstellen.

Schritt 2: Schreiben Sie den folgenden Code in die Python-Datei create_directory.py .
fromsnakebite.clientimportClientclient=Client('localhost',9000)forpinclient.mkdir(['/demo/demo1','/demo2'], create_parent=True):p
Das mkdir() enthält eine Liste der Pfade der Verzeichnisse, die erstellt werden sollen. create_parent = True stellt sicher, dass das übergeordnete Verzeichnis, wenn es nicht erstellt wird, zuerst erstellt wird. In unserem Fall wird zuerst das Demoverzeichnis erstellt, und dann wird demo1 darin erstellt.

Schritt 3: Führen Sie die Datei create_directory.py aus und beobachten Sie das Ergebnis.
python create_directory.py // Dadurch werden Verzeichnisse erstellt, wie im Argument mkdir() erwähnt.

Im obigen Bild 'Ergebnis': True gibt an, dass wir das Verzeichnis erfolgreich erstellt haben.
Schritt 4: Wir können überprüfen, ob die Verzeichnisse erstellt wurden oder nicht, entweder manuell oder mit dem folgenden Befehl.
hdfs dfs -ls / // listet alle Verzeichnisse im Stammordner auf hdfs dfs -ls / demo // listet alle im Demo-Ordner vorhandenen Verzeichnisse auf
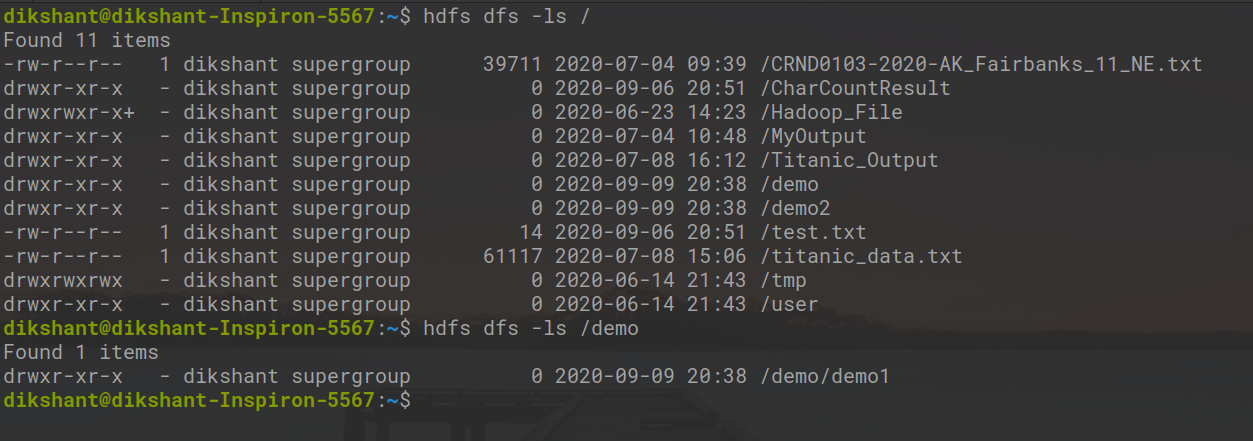
Im obigen Bild können wir beobachten, dass wir alle Verzeichnisse erfolgreich erstellt haben.