BERT verstehen – NLP
BERT steht für Bidirectional Representation for Transformers . Es wurde 2018 von Forschern bei Google Research vorgeschlagen. Obwohl das Hauptziel darin bestand, das Verständnis der Bedeutung von Suchrequestsn im Zusammenhang mit der Google-Suche zu verbessern. Eine Studie zeigt, dass Google jeden Tag 15 % der neuen Suchrequestsn erhält. Daher muss die Google-Suchmaschine ein viel besseres Sprachverständnis haben, um die Suchrequests zu verstehen.
Um das Sprachverständnis des Modells zu verbessern. BERT wird für verschiedene Aufgaben auf einer anderen Architektur trainiert und getestet. Einige dieser Aufgaben mit der unten diskutierten Architektur.
Masked Language Model:
In dieser NLP-Aufgabe ersetzen wir 15 % der Wörter im Text durch das [MASK]-Token. Das Modell sagt dann die ursprünglichen Wörter voraus, die durch [MASK]-Token ersetzt werden. Über das Maskieren hinaus mischt das Maskieren die Dinge auch ein wenig, um die spätere Feinabstimmung des Modells zu verbessern, da das [MASK]-Token eine Diskrepanz zwischen Training und Feinabstimmung verursacht hat. In diesem Modell fügen wir oben am Encoder-Eingang eine Klassifizierungsebene hinzu. Wir berechnen auch die Wahrscheinlichkeit der Ausgabe unter Verwendung einer vollständig verbundenen und einer Softmax-Schicht. Maskiertes Sprachmodell: Die BERT-Verlustfunktion berücksichtigt bei ihrer Berechnung nur die Vorhersage maskierter Werte und ignoriert die Vorhersage der nicht maskierten Werte. Dies hilft bei der Berechnung des Verlusts nur für diese 15 % maskierten Wörter. Vorhersage des nächsten Satzes:
In dieser NLP-Aufgabe werden uns zwei Sätze zur Verfügung gestellt, unser Ziel ist es, vorherzusagen, ob der zweite Satz der nächste Folgesatz des ersten Satzes im Originaltext ist. Während des Trainings des BERT nehmen wir 50 % der Daten, die der nächste nachfolgende Satz (mit der Bezeichnung "isNext") sind, aus dem ursprünglichen Satz und 50 % der Zeit nehmen wir den zufälligen Satz, der nicht der nächste Satz im Originaltext ist (mit der Bezeichnung " als NotNext). Da dies eine Klassifizierungsaufgabe ist, ist das erste Token das [CLS]-Token. Dieses Modell verwendet auch ein [SEP]-Token, um die beiden Sätze zu trennen, die wir an das Modell übergeben haben.
Das BERT-Modell erreichte bei dieser Aufgabe eine Genauigkeit von 97 % bis 98 %. Der Vorteil des Trainierens des Modells mit der Aufgabe besteht darin, dass es dem Modell hilft, die Beziehung zwischen Sätzen zu verstehen.
Feinabstimmung von BERT für unterschiedliche Aufgaben –
- BERT für Satzpaar
- MNLI: Multi-Genre Natural Language Inference ist eine großangelegte Klassifikationsaufgabe. In dieser Aufgabe haben wir ein Paar des Satzes gegeben. Das Ziel besteht darin, festzustellen, ob der zweite Satz in Bezug auf den ersten Satz eine Konsequenz, ein Widerspruch oder neutral ist.
- QQP : Quora Question Pairs, In diesem Datensatz soll festgestellt werden, ob zwei Fragen semantisch gleich sind.
- QNLI : Question Natural Language Inference, In dieser Aufgabe muss das Modell bestimmen, ob der zweite Satz die Antwort auf die im ersten Satz gestellte Frage ist.
- SWAG : Situations With Adversarial Generations Dataset enthält 113.000 Satzklassifikationen. Die Aufgabe besteht darin, festzustellen, ob der zweite Satz die Fortsetzung des ersten ist oder nicht.
-Klassifizierungsaufgabe: BERT hat seine Architektur für eine Reihe von Satzpaar-Klassifizierungsaufgaben optimiert, wie zum Beispiel:

- Einzelsatz-Klassifizierungsaufgabe:
- SST-2: Die Stanford Sentiment Treebank ist eine binäre Satzklassifikationsaufgabe, die aus Sätzen besteht, die aus Filmrezensionen extrahiert wurden, mit Anmerkungen zu ihrer Stimmung, die im Satz dargestellt wird. BERT generierte hochmoderne Ergebnisse auf SST-2.
- CoLA: Das Corpus of Linguistic Acceptability ist die binäre Klassifikationsaufgabe. Das Ziel dieser Aufgabe ist es, vorherzusagen, ob ein bereitgestellter englischer Satz sprachlich akzeptabel ist oder nicht.

- Frage-Antwort-Aufgabe: BERT hat auch Frage-Antwort-Aufgaben nach dem neuesten Stand der Technik generiert, wie z. B. Stanford-Frage-Antwort-Datensätze (SQuAD v1.1 und SQuAD v2.0). Bei dieser Frage-Antwort-Aufgabe nimmt das Modell eine Frage und eine Passage. Ziel ist es, die Antworttextspanne in der Frage zu markieren.
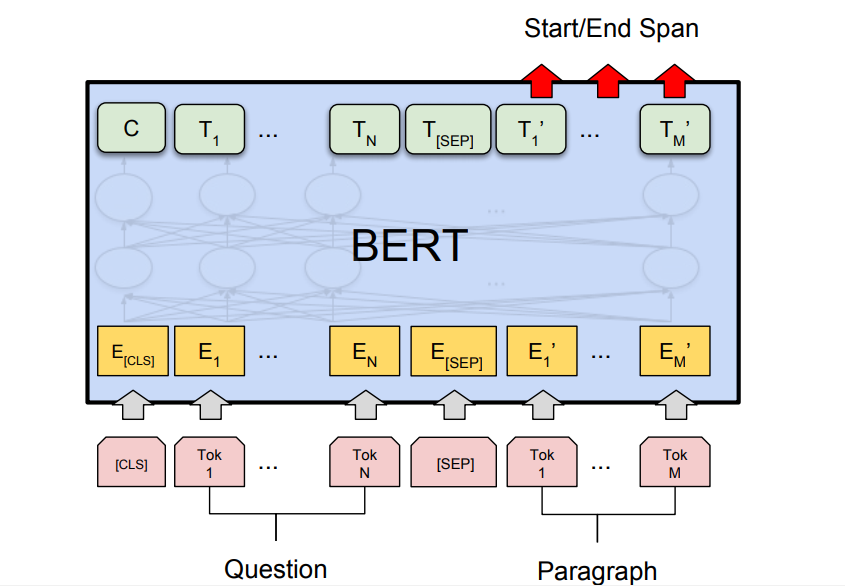
BERT für die Google-Suche:
Wie wir oben besprochen haben, wird BERT trainiert und generiert State-of-the-Art-Ergebnisse für die Frage-Antwort-Aufgabe. Dies war insbesondere auf die Transformer-Modelle zurückzuführen, die wir in der BERT-Architektur verwendet haben. Diese Modelle verwenden ganze Sätze als Eingaben anstelle von Wort-für-Wort-Eingaben. Dies hilft bei der Generierung vollständiger kontextbezogener Einbettungen eines Wortes und hilft, die Sprache besser zu verstehen. Diese Methode ist sehr nützlich, um die wahre Absicht hinter der Suchrequests zu verstehen, um die besten Ergebnisse zu liefern. BERT-Suchrequests Aus dem obigen Bild können wir ersehen, dass Google nach Anwendung des BERT-Modells die Suchrequests besser versteht und daher ein genaueres Ergebnis liefert.
Schlussfolgerung:
BERT hat sich als ein Durchbruch auf dem Gebiet der Verarbeitung natürlicher Sprache und des Sprachverständnisses erwiesen, ähnlich wie AlexNet es auf dem Gebiet der maschinellen Bildverarbeitung gebracht hat. Es hat in verschiedenen Aufgabenstellungen hochmoderne Ergebnisse erzielt und kann daher für viele NLP-Aufgaben verwendet werden. Seit Dezember 2019 wird es auch in der Google-Suche in 70 Sprachen verwendet. Referenzen: