Persönlicher Sprachassistent in Python
Wie wir wissen, ist Python eine geeignete Sprache für Drehbuchautoren und Entwickler. Lassen Sie uns mit Python ein Skript für Personal Voice Assistant schreiben. Die Abfrage für den Assistenten kann je nach Bedarf des Benutzers bearbeitet werden.
Der implementierte Assistent kann die Anwendung öffnen (sofern sie im System installiert ist), Google, Wikipedia und YouTube nach der Abfrage durchsuchen, mathematische Fragen berechnen usw., indem er einfach den Sprachbefehl erteilt . Wir können die Daten nach Bedarf verarbeiten oder die Funktionalität hinzufügen, je nachdem, wie wir die Dinge codieren.
Wir verwenden die Google Spracherkennungs-API und Google Text to Speech für die Spracheingabe bzw. -ausgabe. Zur
Berechnung des mathematischen Ausdrucks kann auch die WolframAlpha-API verwendet werden.
Das Playsound-Paket wird verwendet, um den gespeicherten MP3-Sound vom System abzuspielen.
Anforderungen an externe Python-Pakete:
-> gTTS - Google Text To Speech, zum Konvertieren des angegebenen Textes in Sprache
-> Spracherkennung - zum Erkennen des Sprachbefehls und zum Konvertieren in Text
-> Selen - für webbasierte Arbeit vom Browser
-> Wolframalpha - zur Berechnung durch den Benutzer
-> playound - zum Abspielen der gespeicherten Audiodatei.
-> pyaudio - für Voice Engine in Python
Beginnen wir mit dem Code. Wir werden jede Funktion zum leichteren Verständnis als einen einzigen Code unterteilen.
Hier ist die Hauptfunktion mit get_audio()und assistant_speaks Funktion. get_audio()Die Funktion wurde erstellt, um das Audio vom Benutzer über ein Mikrofon abzurufen. Das Phrasenlimit ist auf 5 Sekunden festgelegt (Sie können es ändern). Die Assistent-Sprechfunktion wird erstellt, um die Ausgabe gemäß den verarbeiteten Daten bereitzustellen.
importspeech_recognition as srimportplaysoundfromgttsimportgTTSimportosimportwolframalphafromseleniumimportwebdrivernum=1defassistant_speaks(output):globalnumnum+=1("PerSon : ", output)toSpeak=gTTS(text=output, lang='en', slow=False)file=str(num)+".mp3toSpeak.save(file)playsound.playsound(file,True)os.remove(file)defget_audio():rObject=sr.Recognizer()audio=''with sr.Microphone() as source:("Speak...")audio=rObject.listen(source, phrase_time_limit=5)("Stop.")try:text=rObject.recognize_google(audio, language='en-US')("You : ", text)returntextexcept:assistant_speaks("Could not understand your audio, PLease try again !")return0if__name__=="__main__":assistant_speaks("What's your name, Human?")name='Human'name=get_audio()assistant_speaks("Hello, "+name+'.')while(1):assistant_speaks("What can i do for you?")text=get_audio().lower()iftext==0:continueif"exit"instr(text)or"bye"instr(text)or"sleep"instr(text):assistant_speaks("Ok bye, "+name+'.')breakprocess_text(text)
Hier sind einige Beispiele und Ausgaben aufgeführt, die Ihnen helfen können, die Funktionsweise der obigen Verarbeitung zu verstehen.
1. Sagen Sie "Google Geeks nach Geeks durchsuchen" 2. Sagen Sie "Spielen Sie Youtube Ihr Lieblingslied" 3. Sagen Sie "Wikipedia Dhoni" 4. Sagen Sie "Microsoft Word öffnen" 5. Sagen Sie "Berechnen Sie alles, was Sie wollen"
In allen oben genannten Fällen wird es tun, was gesagt wird. Wenn der Assistent nicht verstehen kann, was gesagt wird, werden Sie aufgefordert, die Google-Suche durchzuführen. Denn das, was der Assistent nicht kann, wird von diesem Assistenten erledigt.
Unten finden Sie einige Screenshots für das Gespräch zwischen Mensch und Assistent.
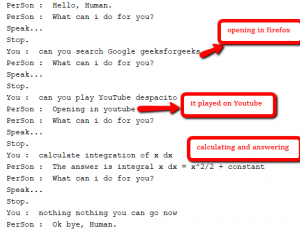

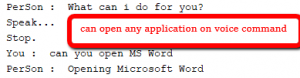
Das war's. Die oben genannte Funktionalität kann auf viele Arten codiert werden. Dies ist eine grundlegende Implementierung. Stellen Sie sicher, dass Sie über die neueste Version aller oben genannten Pakete verfügen, damit Sie reibungslos arbeiten können. Um den obigen Code auszuführen, kombinieren Sie alle Funktionen in derselben Datei.
Nachfolgend finden Sie ein kurzes Video zur Zusammenstellung des obigen Codes.