R-CNN | Regionale CNNs
Da Convolution Neural Network (CNN) mit einer vollständig verbundenen Schicht nicht in der Lage ist, mit der Häufigkeit des Auftretens und mehreren Objekten umzugehen. Ein Weg könnte sein, dass wir eine Brute-Force-Suche mit Schiebefenstern verwenden, um eine Region auszuwählen und das CNN-Modell darauf anzuwenden. Das Problem dieses Ansatzes besteht jedoch darin, dass dasselbe Objekt in einem Bild mit unterschiedlichen Größen und unterschiedlichen Aspekten dargestellt werden kann Verhältnis. Unter Berücksichtigung dieser Faktoren haben wir viele Vorschläge für Regionen und wenn wir Deep Learning (CNN) auf alle Regionen anwenden, die rechenintensiv wären.
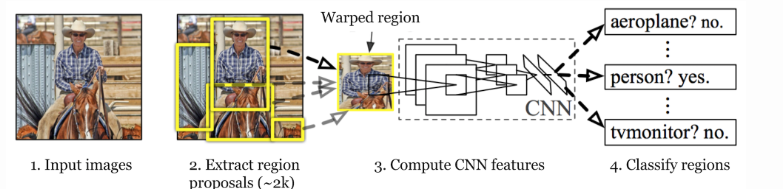
R-CNN-Architektur
Ross Girshick et al. 2013 wurde eine Architektur namens R-CNN (Region-based CNN) vorgeschlagen, um diese Herausforderung der Objekterkennung zu bewältigen. Diese R-CNN-Architektur verwendet den selektiven Suchalgorithmus, der ungefähr 2000 Regionsvorschläge generiert . Diese Vorschläge für 2000 Regionen werden dann der CNN-Architektur zur Verfügung gestellt, die CNN-Merkmale berechnet. Diese Features werden dann in einem SVM-Modell übergeben, um das im Regionsvorschlag vorhandene Objekt zu klassifizieren. Ein zusätzlicher Schritt besteht darin, einen Begrenzungsrahmen-Regressor auszuführen, um die im Bild vorhandenen Objekte genauer zu lokalisieren.
Regionsvorschläge:
Regionsvorschläge sind einfach die kleineren Regionen des Bildes, die möglicherweise die Objekte enthalten, nach denen wir im Eingabebild suchen. Um die Regionsvorschläge im R-CNN zu reduzieren, wird ein gieriger Algorithmus verwendet, der als selektive Suche bezeichnet wird.
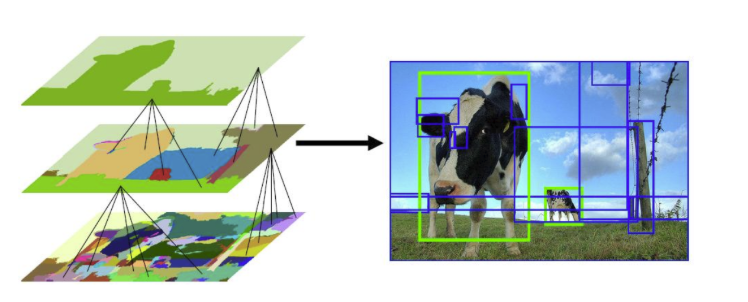 Generierung von Regionsvorschlägen mithilfe der selektiven Suche (Bildquelle: Link )
Generierung von Regionsvorschlägen mithilfe der selektiven Suche (Bildquelle: Link )
Selektive Suche: Die
selektive Suche ist ein gieriger Algorithmus, der kleinere segmentierte Regionen kombiniert, um einen Regionsvorschlag zu generieren. Dieser Algorithmus nimmt ein Bild als Eingabe und Ausgabe, um Regionsvorschläge darauf zu generieren. Dieser Algorithmus hat gegenüber der zufälligen Angebotserstellung den Vorteil, dass er die Anzahl der Vorschläge auf ungefähr 2000 begrenzt und diese Regionsvorschläge einen hohen Rückruf aufweisen.
Algorithmus:
- Generieren Sie eine anfängliche Untersegmentierung des Eingabebildes.
- Kombinieren Sie ähnliche Begrenzungsrahmen zu größeren rekursiven
- Verwenden Sie diese größeren Felder, um Regionsvorschläge für die Objekterkennung zu generieren.
In Schritt 2 werden Ähnlichkeiten basierend auf Farbähnlichkeit, Texturähnlichkeit, Regionsgröße usw. betrachtet. Wir haben den selektiven Suchalgorithmus in diesem Artikel ausführlich erörtert .
CNN-Architektur von R-CNN:
Danach werden diese Regionen gemäß dem CNN-Modell in das einzelne Quadrat der Dimensionsregionen verzogen. Das CNN-Modell, das wir hier verwendet haben, ist ein vorab trainiertes AlexNet-Modell, das zu diesem Zeitpunkt das CNN-Modell auf dem neuesten Stand der Technik für die Bildklassifizierung ist. Schauen wir uns hier die AlexNet-Architektur an.

Hier ist die Eingabe von AlexNet (227, 227, 3) . Wenn die Regionsvorschläge also klein und groß sind, müssen wir die Größe dieses Regionsvorschlags auf bestimmte Dimensionen ändern.
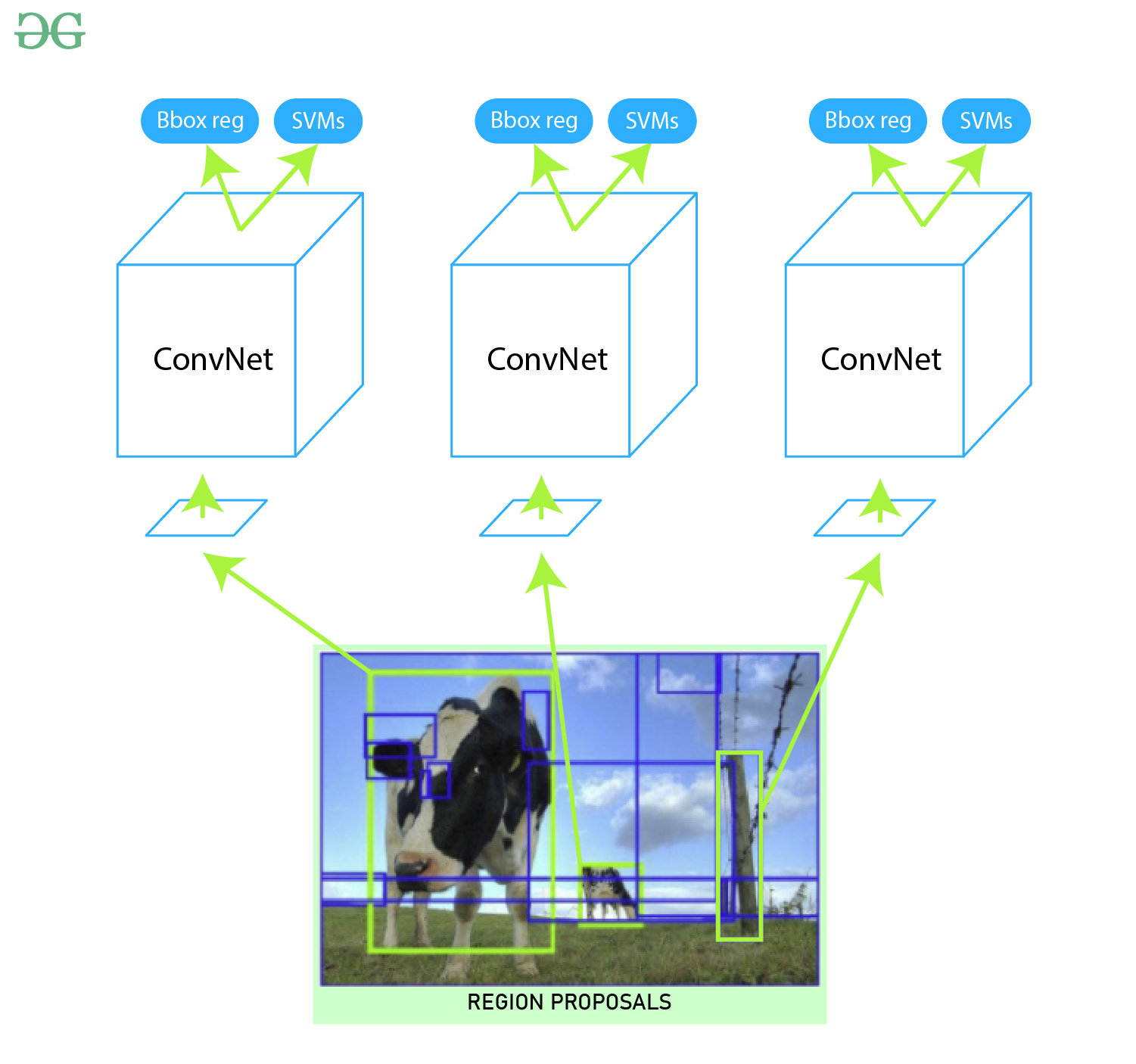
Aus der obigen Architektur entfernen wir die letzte Softmax-Schicht, um den Merkmalsvektor (1, 4096) zu erhalten . Wir übergeben diesen Merkmalsvektor an SVM und Bounding Box Regressor.

SVM (Support Vector Machine):
Der von CNN erzeugte Merkmalsvektor wird dann von der binären SVM verwendet, die für jede Klasse unabhängig trainiert wird. Dieses SVM-Modell verwendet einen in einer früheren CNN-Architektur erzeugten Merkmalsvektor und gibt einen Konfidenzwert für das Vorhandensein eines Objekts in dieser Region aus. Es gibt jedoch ein Problem beim Training mit SVM, dass wir AlexNet-Merkmalsvektoren für das Training der SVM-Klasse benötigten. Daher konnten wir AlexNet und SVM nicht unabhängig voneinander parallel trainieren. Diese Herausforderung wird in zukünftigen Versionen von R-CNN (Fast R-CNN, Faster R-CNN usw.) gelöst.
Bounding Box Regressor:
Um den Bounding Box im Bild genau zu lokalisieren, haben wir ein skalierungsinvariantes lineares Regressionsmodell verwendet, das als Bounding Box Regressor bezeichnet wird. Für das Training dieses Modells nehmen wir wie vorhergesagt und Ground Truth Paare von vier Lokalisierungsdimensionen. Diese Dimensionen sind (x, y, w, h), wobei x und y die Pixelkoordinaten der Mitte des Begrenzungsrahmens sind. w und h stehen für die Breite und Höhe der Begrenzungsrahmen. Diese Methode erhöht die mittlere durchschnittliche Genauigkeit (mAP) des Ergebnisses um 3-4% .
Ausgabe:
Jetzt haben wir Regionsvorschläge, die für jedes Klassenlabel klassifiziert sind. Um den vom obigen Modell erzeugten zusätzlichen Begrenzungsrahmen im Bild zu behandeln, verwenden wir einen Algorithmus namens Nichtmaximale Unterdrückung.
Es funktioniert in 3 Schritten:
- Verwerfen Sie Objekte, bei denen der Konfidenzwert unter einem bestimmten Schwellenwert liegt (z. B. 0,5) .
- Wählen Sie die Region mit der höchsten Wahrscheinlichkeit unter den Kandidatenregionen für das Objekt als vorhergesagte Region aus.
- Im letzten Schritt verwerfen wir die Regionen mit IoU (Schnittpunkt über Union) mit einer vorhergesagten Region über 0,5.

Danach können wir die Ausgabe erhalten, indem wir diese Begrenzungsrahmen auf das Eingabebild zeichnen und Objekte beschriften, die in Begrenzungsrahmen vorhanden sind.
Ergebnisse:
Das R-CNN gibt eine mittlere durchschnittliche Genauigkeit (mAPs) von 53,7% für den VOC 2010-Datensatz an. Für den ILSVRC 2013- Objekterkennungsdatensatz der 200-Klasse ergibt sich ein mAP von 31,4%, was eine große Verbesserung gegenüber den vorherigen besten 24,3% darstellt . Diese Architektur ist jedoch sehr langsam zu trainieren und benötigt ~ 49 Sekunden , um Testergebnisse für ein einzelnes Bild des VOC 2007-Datasets zu generieren.
Herausforderungen von R-CNN:
- Der selektive Suchalgorithmus ist sehr starr und es findet kein Lernen statt. Dies führt manchmal zur Erzeugung von Vorschlägen für schlechte Regionen zur Objekterkennung.
- Da gibt es ca. 2000 Kandidatenvorschläge. Das Trainieren des Netzwerks nimmt viel Zeit in Anspruch. Außerdem müssen wir mehrere Schritte separat trainieren (CNN-Architektur, SVM-Modell, Bounding-Box-Regressor). Dies macht die Implementierung sehr langsam.
- R-CNN kann nicht in Echtzeit verwendet werden, da das Testen eines Bildes mit einem Bounding-Box-Regressor ungefähr 50 Sekunden dauert .
- Da müssen wir Feature-Maps aller Regionsvorschläge speichern. Es erhöht auch den Speicherbedarf während des Trainings.
Verweise:
