Vorhersage der Richtung des Aktienkurses mithilfe von Support Vector Machines
Wir werden ein End-to-End-Projekt mit Support Vector Machines implementieren, um den Handel für uns zu leben. Wahrscheinlich haben Sie schon einmal von dem Begriff Aktienmarkt gehört, von dem bekannt ist, dass er das Leben von Tausenden gemacht und das Leben von Millionen zerstört hat. Wenn Sie mit der Börse nicht vertraut sind, können Sie einige grundlegende Dinge über Märkte surfen.
Verwendete Tools und Technologien:
- Python
- Sklearn- Support Vector Classifier
- Yahoo Finanzen
- Jupyter-Notebook
- Blauverschiebung
Schritt für Schritt Umsetzung
Schritt 1: Importieren Sie die Bibliotheken
Python3
# Machine learning
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# For data manipulation
import pandas as pd
import numpy as np
# To plot
import matplotlib.pyplot as plt
plt.style.use('seaborn-darkgrid')
# To ignore warnings
import warnings
warnings.filterwarnings("ignore")
Schritt 2: Bestandsdaten lesen
Wir werden die von der Yahoo Finance-Website heruntergeladenen Aktiendaten lesen. Die Daten werden im OHLC-Format (Open, High, Low, Close) in einer CSV-Datei gespeichert. Um eine CSV-Datei zu lesen, können Sie die Methode read_csv() von Pandas verwenden.
Syntax :
pd.read_csv(filename, index_col)
Hinweis: Wir haben die Daten der letzten 1 Jahr von Reliance Industries Trading In NSE von der Yahoo Finance Website heruntergeladen.
Verwendete Datei:
Python3
# Read the csv file using read_csv
# method of pandas
df = pd.read_csv('RELIANCE.csv')
df
Ausgabe:
Schritt 3: Datenaufbereitung
Die Daten mussten vor der Verwendung verarbeitet werden, sodass die Datumsspalte als Index dafür dienen sollte
Python3
# Changes The Date column as index columns df.index = pd.to_datetime(df['Date']) df # drop The original date column df = df.drop(['Date'], axis='columns') df
Ausgabe:
Schritt 4: Definieren Sie die erklärenden Variablen
Erklärende oder unabhängige Variablen werden verwendet, um die Wertantwortvariable vorherzusagen. Das X ist ein Datensatz, der die Variablen enthält, die für die Vorhersage verwendet werden. Das X besteht aus Variablen wie „Open – Close“ und „High – Low“. Diese können als Indikatoren verstanden werden, anhand derer der Algorithmus den Trend von morgen vorhersagt. Fühlen Sie sich frei, weitere Indikatoren hinzuzufügen und die Leistung zu sehen
Python3
# Create predictor variables df['Open-Close'] = df.Open - df.Close df['High-Low'] = df.High - df.Low # Store all predictor variables in a variable X X = df[['Open-Close', 'High-Low']] X.head()
Ausgabe:
Schritt 5: Definieren Sie die Zielvariable
Die Zielvariable ist das Ergebnis, das das maschinelle Lernmodell basierend auf den erklärenden Variablen vorhersagt. y ist ein Zieldatensatz, der das richtige Handelssignal speichert, das der maschinelle Lernalgorithmus vorherzusagen versucht. Wenn der Kurs von morgen höher ist als der Kurs von heute, dann kaufen wir die betreffende Aktie, andernfalls haben wir keine Position in der Aktie. Wir speichern +1 für ein Kaufsignal und 0 für eine Nein-Position in y. Dazu verwenden wir die Funktion where() von NumPy.
Syntax:
np.where(condition,value_if_true,value_if_false)
Python3
# Target variables y = np.where(df['Close'].shift(-1) > df['Close'], 1, 0) y
Ausgabe:

Schritt 6: Teilen Sie die Daten in Trainieren und Testen auf
Wir teilen die Daten in Trainings- und Testdatensätze auf. Dies geschieht, damit wir die Effektivität des Modells im Testdatensatz bewerten können
Python3
split_percentage = 0.8 split = int(split_percentage*len(df)) # Train data set X_train = X[:split] y_train = y[:split] # Test data set X_test = X[split:] y_test = y[split:]
Schritt 7: Support Vector Classifier (SVC)
Wir verwenden die SVC()-Funktion aus der sklearn.svm.SVC- Bibliothek, um unser Klassifikatormodell mit der fit()-Methode für den Trainingsdatensatz zu erstellen.
Python3
# Support vector classifier cls = SVC().fit(X_train, y_train)
Schritt 8: Genauigkeit des Klassifikators
Wir werden die Genauigkeit des Algorithmus im Zug berechnen und den Datensatz testen, indem wir die tatsächlichen Werte des Signals mit den vorhergesagten Werten des Signals vergleichen. Die Funktion precision_score() wird verwendet, um die Genauigkeit zu berechnen.

Eine Genauigkeit von über 50 % der Testdaten deutet darauf hin, dass das Klassifikatormodell effektiv ist.
Schritt 9: Strategieumsetzung
Wir werden das Signal (Kauf oder Verkauf) mit der Funktion cls.predict() vorhersagen.
Python3
df['Predicted_Signal'] = cls.predict(X)
Berechnen Sie die tägliche Rendite
Python3
# Calculate daily returns df['Return'] = df.Close.pct_change()
Berechnen Sie Strategierenditen
Python3
# Calculate strategy returns df['Strategy_Return'] = df.Return *df.Predicted_Signal.shift(1)
Kumulative Renditen berechnen
Python3
# Calculate Cumulutive returns df['Cum_Ret'] = df['Return'].cumsum() df
Berechnen Sie die kumulierten Renditen der Strategie
Python3
# Plot Strategy Cumulative returns df['Cum_Strategy'] = df['Strategy_Return'].cumsum() df
Zeichnen Sie die Renditen der Strategie im Vergleich zu den ursprünglichen Renditen
Python3
import matplotlib.pyplot as plt %matplotlib inline plt.plot(Df['Cum_Ret'],color='red') plt.plot(Df['Cum_Strategy'],color='blue')
Ausgabe:
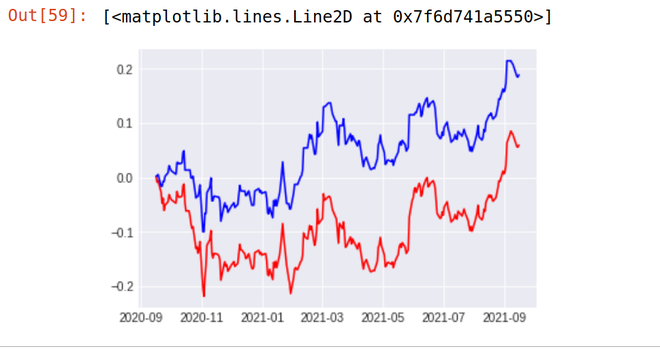
Wie Sie sehen können, scheint unsere Strategie die Performance der Reliance-Aktie vollständig zu übertreffen. Unsere Strategie (blaue Linie) lieferte im letzten Jahr eine Rendite von 18,87 % , während die Aktie von Reliance Industries (rote Linie) im letzten Jahr nur eine Rendite von 5,97 % lieferte .
Backtesting-Ergebnis
1. TKS
Stock Return Over Last 1 year - 48% Strategy result - 48.9 %
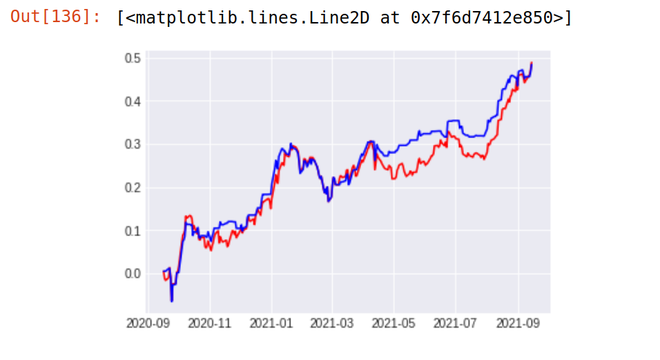
2. ICICI-BANK
Stock Return Over Last 1 year - 48% Strategy result - 48.9 %
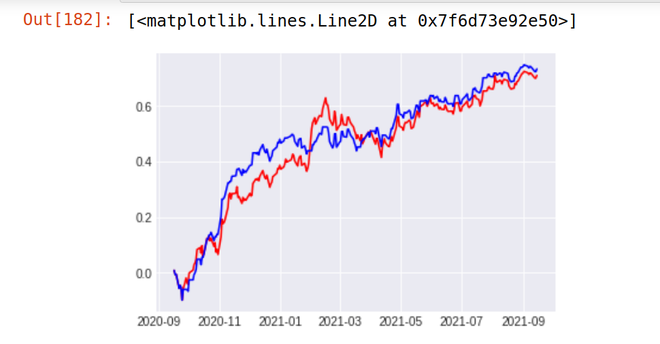
Bereitstellung einer Strategie für den Live-Markt
Die codierte Strategie kann einfach auf dem Live-Markt eingesetzt werden und kann auch an einer beliebigen Anzahl von Daten an allen Börsen rückgetestet werden. Die Bereitstellung kann einfach über die BlueShift-Plattform erfolgen. Es ist eine interaktive Plattform mit Live-Daten-Feed und Verbindungen über verschiedene Broker. Sie können Backtests auf der BlueShift-Plattform beliebig oft mit Daten von verschiedenen Börsen durchführen.
Fazit
- Der Strategieanbieter verspricht Renditen während des Live-Marktes. Derzeit habe ich das Modell nur auf der Grundlage der Niveaus des Vortages trainiert, aber um die Genauigkeit des Modells zu erhöhen, fügen wir auch verschiedene technische Indikatoren zum Trainieren des Modells hinzu, wie RSI, ADX, ATR, MACD, Stochastik und viele mehr.
- Um mehr Genauigkeit auf dem Live-Markt zu erzielen Deep Learning hat sich beim Handel auf einem Live-Markt als sehr effektiv erwiesen. Wir können unsere Trades automatisieren, indem wir Reinforcement Learning und auch Stacked LSTM verwenden, was zu einem exponentiellen Anstieg unserer Strategierenditen führt.
Hinweis: Echtes Geld sollte nicht eingesetzt werden, bis das Backtesting der Strategie abgeschlossen ist und ohne vielversprechende Renditen durch die Strategie während des Papierhandels