XML-Analyse in Python
Dieser Artikel konzentriert sich darauf, wie man eine bestimmte XML-Datei analysieren und einige nützliche Daten strukturiert daraus extrahieren kann.
XML: XML steht für eXtensible Markup Language. Es wurde entwickelt, um Daten zu speichern und zu transportieren. Es wurde so konzipiert, dass es sowohl für Menschen als auch für Maschinen lesbar ist. Aus diesem Grund betonen die Entwurfsziele von XML die Einfachheit, Allgemeinheit und Benutzerfreundlichkeit im Internet.
Die in diesem Lernprogramm zu analysierende XML-Datei ist eigentlich ein RSS-Feed.
RSS: RSS (Rich Site Summary, oft als Really Simple Syndication bezeichnet) verwendet eine Familie von Standard-Webfeed-Formaten, um häufig aktualisierte Informationen wie Blogeinträge, Schlagzeilen, Audio und Video zu veröffentlichen. RSS ist XML-formatierter Klartext.
- Das RSS-Format selbst ist sowohl für automatisierte Prozesse als auch für Menschen relativ einfach zu lesen.
- Das in diesem Tutorial verarbeitete RSS ist der RSS-Feed der wichtigsten Nachrichten von einer beliebten Nachrichten-Website. Sie können es hier überprüfen . Unser Ziel ist es, diesen RSS-Feed (oder diese XML-Datei) zu verarbeiten und in einem anderen Format für die zukünftige Verwendung zu speichern.
Python - Modul verwendet: Dieser Artikel konzentriert sich auf die Verwendung von eingebauten XML - Modul in Python für das Parsen von XML und der Schwerpunkt wird auf der sein ElementTree XML API dieses Moduls.
Implementierung:
importcsvimportrequestsimportxml.etree.ElementTree as ETdefloadRSS():url='http://www.hindustantimes.com/rss/topnews/rssfeed.xml'resp=requests.get(url)withopen('topnewsfeed.xml','wb') as f:f.write(resp.content)defparseXML(xmlfile):tree=ET.parse(xmlfile)root=tree.getroot()newsitems=[]foriteminroot.findall('./channel/item'):news={}forchildinitem:ifchild.tag=='{http://search.yahoo.com/mrss/}content':news['media']=child.attrib['url']else:news[child.tag]=child.text.encode('utf8')newsitems.append(news)returnnewsitemsdefsavetoCSV(newsitems, filename):fields=['guid','title','pubDate','description','link','media']withopen(filename,'w') as csvfile:writer=csv.DictWriter(csvfile, fieldnames=fields)writer.writeheader()writer.writerows(newsitems)defmain():loadRSS()newsitems=parseXML('topnewsfeed.xml')savetoCSV(newsitems,'topnews.csv')if__name__=="__main__":main()
Der obige Code wird:
- Laden Sie den RSS-Feed von der angegebenen URL und speichern Sie ihn als XML-Datei.
- Analysieren Sie die XML-Datei, um Nachrichten als Liste von Wörterbüchern zu speichern, wobei jedes Wörterbuch eine einzelne Nachricht ist.
- Speichern Sie die Nachrichten in einer CSV-Datei.
Versuchen wir, den Code in Teilen zu verstehen:
- Laden und Speichern von RSS-Feeds
def loadRSS(): # URL des RSS-Feeds url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # Erstellen eines HTTP-Antwortobjekts aus der angegebenen URL resp = request.get (url) # Speichern der XML-Datei mit open ('topnewsfeed.xml', 'wb') als f: f.write (bzw. Inhalt)Hier haben wir zuerst ein HTTP-Antwortobjekt erstellt, indem wir eine HTTP-Anforderung an die URL des RSS-Feeds gesendet haben. Der Inhalt der Antwort enthält jetzt die XML- Dateidaten, die wir als topnewsfeed.xml in unserem lokalen Verzeichnis speichern .
Weitere Informationen zur Funktionsweise des Anforderungsmoduls finden Sie in diesem Artikel:
GET- und POST-Anforderungen mit Python
- XML
analysieren Wir haben die Funktion parseXML() erstellt , um XML-Dateien zu analysieren. Wir wissen, dass XML ein inhärent hierarchisches Datenformat ist, und die natürlichste Art, es darzustellen, ist die Verwendung eines Baums. Schauen Sie sich das Bild unten zum Beispiel an:
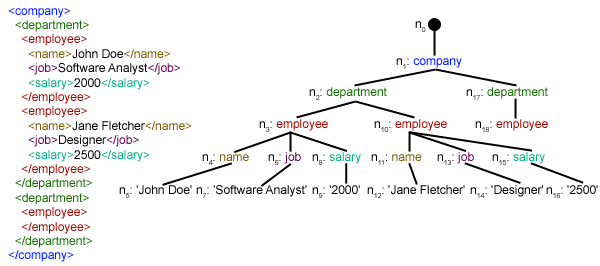
Hier verwenden wir das Modul xml.etree.ElementTree (kurz ET). Element Tree verfügt zu diesem Zweck über zwei Klassen: ElementTree repräsentiert das gesamte XML-
Dokument als Baum und Element repräsentiert einen einzelnen Knoten in diesem Baum. Interaktionen mit dem gesamten Dokument (Lesen und Schreiben in / aus Dateien) werden normalerweise auf ElementTree- Ebene durchgeführt. Interaktionen mit einem einzelnen XML-Element und seinen Unterelementen werden für das Element ausgeführt durchgeführt.Ok, also lass uns die parseXML() durchgehen. Funktion :
tree = ET.parse (xmlfile)
Hier erstellen wir ein ElementTree- Objekt, indem wir das übergebene Objekt analysieren XML-Datei analysieren.
root = tree.getroot()
Die Funktion getroot() gibt die Wurzel des Baums als Element zurück - Objekt.
für Element in root.findall ('./ channel / item'):Nun, wenn Sie einen Blick auf die Struktur Ihrer XML - Datei aufgenommen haben, werden Sie feststellen , dass wir nur interessiert sind Artikel Element.
./channel/item ist eigentlich die XPath- Syntax (XPath ist eine Sprache zum Adressieren von Teilen eines XML-Dokuments). Hier möchten wir alle Item -Enkelkinder von Channel- Childs des Root- Elements (mit '.' Bezeichnet) finden.
Weitere Informationen zur unterstützten XPath-Syntax finden Sie hier .
für Element in root.findall ('./ channel / item'): # leeres Nachrichtenwörterbuch news = {} # untergeordnete Elemente des Elements iterieren für Kind im Artikel: # Spezielle Überprüfung auf Namespace-Objektinhalte: Medien if child.tag == '{http://search.yahoo.com/mrss/}content': news ['media'] = child.attrib ['url'] sonst: news [child.tag] = child.text.encode ('utf8') # Nachrichtenwörterbuch an Nachrichtenliste anhängen newsitems.append (Nachrichten)Jetzt wissen wir , dass wir durch iterieren Artikel Elemente , wobei jedes Element Element eine Nachricht enthält. Daher erstellen wir ein leeres Nachrichtenwörterbuch, in dem wir alle verfügbaren Daten zu Nachrichten speichern. Um jedes untergeordnete Element eines Elements zu durchlaufen, durchlaufen wir es einfach wie folgt:
für Kind im Artikel:
Beachten Sie nun hier ein Beispielelementelement:

Wir müssen Namespace-Tags separat behandeln, wenn sie beim Analysieren auf ihren ursprünglichen Wert erweitert werden. Also machen wir so etwas:
if child.tag == '{http://search.yahoo.com/mrss/}content': news ['media'] = child.attrib ['url']child.attrib ist ein Wörterbuch aller Attribute, die sich auf ein Element beziehen. Hier interessieren wir uns für das URL- Attribut von media: content namespace tag.
Jetzt machen wir für alle anderen Kinder einfach:news [child.tag] = child.text.encode ('utf8')child.tag enthält den Namen des untergeordneten Elements. child.text speichert den gesamten Text in diesem untergeordneten Element. Schließlich wird ein Beispielelementelement in ein Wörterbuch konvertiert und sieht folgendermaßen aus:
{'description': 'Ignis hat bereits eine harte Konkurrenz von Hyun ...., 'guid': 'http: //www.hindustantimes.com/autos/maruti-ignis-launch ...., 'link': 'http: //www.hindustantimes.com/autos/maruti-ignis-launch ...., 'media': 'http: //www.hindustantimes.com/rf/image_size_630x354/HT / ..., 'pubDate': 'Do, 12. Januar 2017, 12:33:04 GMT', 'title': 'Maruti Ignis startet am 13. Januar: Fünf Autos, die bedrohen .....}Dann hängen wir dieses Dikt-Element einfach an die Listen- Newsitems an .
Schließlich wird diese Liste zurückgegeben. - Speichern von Daten in einer CSV-Datei
Jetzt speichern wir einfach die Liste der Nachrichten in einer CSV-Datei, damit sie in Zukunft mithilfe der Funktion savetoCSV() problemlos verwendet oder geändert werden können . Weitere Informationen zum Schreiben von Wörterbuchelementen in eine CSV-Datei finden Sie in diesem Artikel:
Arbeiten mit CSV-Dateien in Python
So sehen unsere formatierten Daten jetzt aus:

Wie Sie sehen können, wurden die hierarchischen XML-Dateidaten in eine einfache CSV-Datei konvertiert, sodass alle Nachrichten in Form einer Tabelle gespeichert werden. Dies erleichtert auch die Erweiterung der Datenbank.
Außerdem kann man die JSON-ähnlichen Daten direkt in ihren Anwendungen verwenden! Dies ist die beste Alternative zum Extrahieren von Daten von Websites, die keine öffentliche API, aber einige RSS-Feeds bereitstellen.
Alle im obigen Artikel verwendeten Codes und Dateien finden Sie hier .
Was als nächstes?
- Sie können sich weitere RSS-Feeds der im obigen Beispiel verwendeten Nachrichten-Website ansehen. Sie können versuchen, eine erweiterte Version des obigen Beispiels zu erstellen, indem Sie auch andere RSS-Feeds analysieren.
- Bist du ein Cricket-Fan? Dann muss dieser RSS-Feed von Ihrem Interesse sein! Sie können diese XML-Datei analysieren, um Informationen über die Live-Cricket-Spiele zu sammeln und einen Desktop-Notifier zu erstellen!
Dieser Artikel wurde von Nikhil Kumar verfasst. Wenn Ihnen GeeksforGeeks gefällt und Sie einen Beitrag leisten möchten, können Sie auch einen Artikel schreiben und Ihren Artikel an contrib@geeksforgeeks.org senden. Sehen Sie sich Ihren Artikel auf der GeeksforGeeks-Hauptseite an und helfen Sie anderen Geeks.
Bitte schreiben Sie Kommentare, wenn Sie etwas Falsches finden oder weitere Informationen zu dem oben diskutierten Thema teilen möchten
